Concepts
Cette section décrit les concepts que vous devez comprendre pour effectuer une mise en œuvre de RAC/M Identity. Elle vous guide dans l'identification des sources faisant autorité pour les identités, l'identification et l'intégration des systèmes cibles et la mise en œuvre d'une logique d'affaires de base pour effectuer la collecte initiale des données en vue de la création du référentiel de RAC/M Identity.
À propos des gens et des identités
En gestion des identités, il est essentiel de distinguer la personne physique des différentes relations ou affiliations qu'elle peut entretenir avec une organisation. Cette distinction constitue le fondement d'une gouvernance rigoureuse des identités et des accès.
Dans bien des cas, la relation est simple : les personnes qui travaillent pour une organisation sont des employés, celles qui étudient dans une école ou une université sont des étudiants, et celles qui reçoivent des soins dans un hôpital sont des patients. Dans d'autres situations, toutefois, la frontière est moins nette. Une personne peut être à la fois étudiante et membre du personnel d'une université, ou travailler pour une organisation à titre d'entrepreneur plutôt que comme employée. Les combinaisons possibles de relations entre les personnes et les organisations sont pratiquement illimitées.
Ces relations obéissent également à un cycle de vie : elles ont un début et une fin définis, et elles sont généralement gérées ou supervisées par une ou plusieurs personnes au sein d'un service ou d'une unité d'affaires précise de l'organisation.
Dans RAC/M Identity, le terme Personne désigne l'individu physique, alors que le terme Identité désigne chacune des relations ou affiliations que cette personne entretient avec l'organisation. Une même Personne peut donc être associée à une ou plusieurs Identités, reflétant les différentes qualités dans lesquelles elle interagit avec l'organisation.
Note
Le terme personas est couramment utilisé dans le domaine de la gestion des identités pour désigner le même concept que RAC/M Identity nomme identités.
Identité unique ou identités multiples
RAC/M Identity prend en charge les deux approches de modélisation de la relation entre une personne et l'organisation :
- Dans le modèle à identité unique, chaque personne physique ne possède qu'une seule identité dans le référentiel, et les différentes relations qu'elle entretient sont distinguées au moyen de rôles.
- Dans le modèle à identités multiples, une personne physique peut détenir plusieurs identités simultanément, chacune représentant une relation distincte avec l'organisation.
Puisque les relations ont généralement un début et une fin définis, une identité est considérée comme active entre sa date de début et sa date de fin, et comme inactive avant la date de début ou après la date de fin.
L'un des principaux avantages du modèle à identités multiples est la traçabilité qu'il offre sur les affiliations et les droits d'accès qu'une personne a détenus au fil du temps. Lorsqu'une relation atteint sa date de fin, l'identité correspondante devient inactive. Si la même personne revient ultérieurement dans l'organisation — par exemple, un employé saisonnier ou un étudiant qui reprend ses études après une pause — une nouvelle identité active est créée, héritant de nombreux paramètres de la précédente, comme les identifiants d'utilisateur, l'adresse courriel et d'autres identifiants uniques.
Toutefois, comme la nouvelle identité peut correspondre à une relation entièrement différente, d'autres attributs — tels que le superviseur et le service — sont définis à des valeurs qui décrivent fidèlement l'affiliation courante. Les rôles et les droits d'accès attribués à la nouvelle identité peuvent eux aussi différer, afin de correspondre à ce qui convient à cette nouvelle relation.
Un aspect important de la gestion des identités multiples est que RAC/M Identity ne désactivera pas un compte et ne révoquera pas de droits d'accès lorsqu'une identité devient inactive si le même compte ou les mêmes droits sont également attribués — directement ou indirectement — à une autre identité active de la même personne.
Note
RAC/M Identity surveille en continu l'agrégation des rôles, des droits d'accès, des actifs et d'autres facteurs attribués à une personne à travers l'ensemble de ses identités, et applique les règles de séparation des tâches (Separation of Duties, SoD) afin d'empêcher l'accumulation de comptes, de rôles ou de droits d'accès incompatibles.
Exemple
Prenons l'exemple de Chantal St-Germain. Elle travaille à l'hôpital St-Jude. Elle est à la fois médecin praticien et chercheuse. Ainsi, deux inscriptions ont été créées pour elle dans deux sources d'identités distinctes : la base de données des médecins et la base de données des chercheurs universitaires externes.
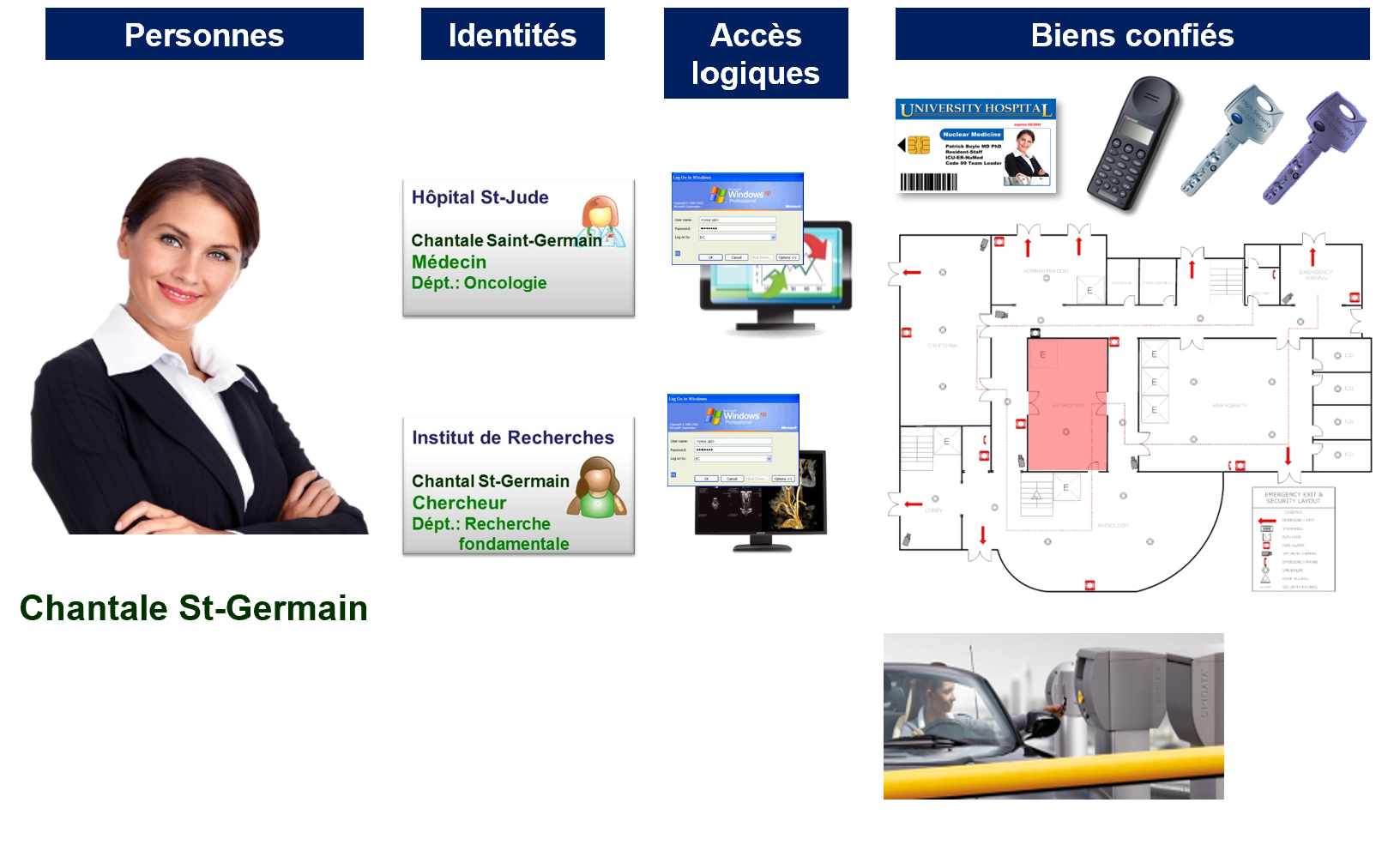
Ces deux identités lui donnent accès à différentes applications (via des comptes et des accès logiques), à des clés physiques et à des zones de l'hôpital.
Les informations trouvées dans ces sources d'identités diffèrent :
- Dans la première source d'identité (qui l'identifie comme un médecin praticien), son nom de famille était orthographié "Saint-Germain".
- Dans la deuxième source d'identité (qui l'identifie comme un chercheur), son nom de famille était orthographié "St-Germain" et la lettre "e" est absente de son prénom.
Bien qu'ils n'aient pas été inscrits de la même façon dans les sources, dans RAC/M Identity, ils sont liés à la même personne et considérés comme Chantale St-Germain.
Comme RAC/M Identity relie ces deux identités à une seule personne, il n'est pas nécessaire de normaliser les différentes identités qui ont été créées dans les systèmes d'origine. Si vous créez une nouvelle identité pour Chantale, elle sera également liée à la bonne personne.
Par conséquent, quand son projet de recherche se terminera, son identité de chercheuse deviendra inactive et les accès correspondants seront révoqués. Mais tous les comptes et accès logiques aux actifs nécessaires pour travailler en tant que médecin, resteront actifs et valides.
Entités non humaines
RAC/M Identity étend la gestion des identités aux entités qui ne sont pas des personnes physiques, mais qui interagissent avec les systèmes d'information. Cela inclut les outils d'automatisation, les charges de travail et les agents IA, ainsi que tout autre type de compte qui n'est pas associé à un individu — comme les comptes de service, de test, de formation et les comptes partagés.
Identités non humaines
Les identités peuvent être désignées comme non humaines au moyen d'un attribut standard ou étendu, et leurs comptes associés peuvent être marqués comme techniques lors du processus de corrélation. Cette approche souple élimine toute restriction sur le nombre et le type d'identités pouvant être gérées, et permet à chaque type d'identité d'être régi par ses propres politiques.
Les identités non humaines sont gérées exactement comme les identités humaines : les superviseurs, réviseurs et administrateurs désignés demeurent responsables de l'application de pratiques de gouvernance rigoureuses, notamment la tenue de révisions d'accès périodiques.
Comptes impersonnels
Les comptes impersonnels sont gérés de la même façon que les comptes personnels ordinaires. Ils sont toutefois attribués à des responsables désignés, qui sont chargés de veiller au respect des politiques de gouvernance applicables. Par exemple, les responsables désignés doivent effectuer des révisions d'accès périodiques des comptes impersonnels qui leur sont confiés.
Identifiants uniques
Chaque objet Personne et chaque Identité dans le référentiel se voit attribuer un identifiant unique permanent généré par le système : un UUID (Universally Unique Identifier), aussi appelé GUID (Globally Unique Identifier). Ces identifiants distinguent durablement chaque entité de toutes les autres et évitent toute ambiguïté lorsque les noms ou d'autres attributs évoluent.
À propos des sources d'identités et des données d'accès
Cette section décrit comment identifier les sources d'identités et d'informations d'acccès ainsi que d'autres données requises pour déployer RAC/M Identity. Des instructions détaillées sur la création, la configuration et la gestion des objets tels que les personnes, les comptes, les actifs et les accès sont fournies dans le Guide d'administration et d'opération.
Identifier les sources d'identités
Vous devez commencer par déterminer les sources autoritaires à partir desquelles vous importerez les informations sur les identités qui peupleront le référentiel d'identités et d'accès.
Les sources d'identités définissent les relations entre les personnes et votre organisation. Les systèmes RH sont des sources d'identités de facto pour les employés, mais il peut y avoir de nombreuses autres sources. En général, les contractuels externes, les stagiaires, les employés temporaires et les utilisateurs de tierces parties ne sont pas gérés par les RH et ne sont pas inclus dans les systèmes RH. Dans la plupart des cas, il faut identifier d'autres sources où l'on peut trouver un minimum d'informations sur ces identités.
Souvent, Active Directory, ENTRA ID, les bases de données SQL et même les feuilles de calcul Excel peuvent être utilisées comme sources d'identités pour les non-employés.
En utilisant les informations trouvées dans les sources d'identités, telles que les dates de début et de fin d'un interne dans un hôpital ou le poste d'une personne dans le système des ressources humaines, vous serez en mesure de définir les identités d'une personne.
Les sources d'identités peuvent être des fichiers ou des listes de personnes impliquées dans l'organisation, par exemple :
- Employés
- Consultants
- Partenaires
- Stagiaires
- Étudiants
- Fournisseurs
- Contractuels
- Clients
- Toute autre personne ou entité nécessitant un accès aux services, aux applications informatiques ou aux biens matériels.
Les sources d'identités peuvent provenir de divers endroits, tels que :
- Le département des ressources humaines
- Base de données d'inscription des étudiants universitaires
- Liste des médecins et des internes d'un hôpital
- Tout autre département ou service pouvant fournir une liste de personnes ayant besoin d'accéder à des services, applications informatiques ou biens physiques.
Note
Lorsqu'une identité est trouvée dans plus d'une source, il y a généralement une source qui est la plus fiable ou la plus complète. Dans ce cas, vous devez déterminer la source la plus utile.
Les informations associées à une personne peuvent être obtenues de plusieurs sources.
Pour chaque source, vous devez déterminer quelles sont les tables et les attributs de base de données pertinents et comment les importer dans RAC/M Identity. Des modèles préétablis pour les systèmes RH populaires tels que SAP sont disponibles pour accélérer le processus d'intégration. Avec l'édition RAC/M Identity Premium, des connecteurs aux sources d'identités sont généralement mis en œuvre, tandis que des collecteurs et des fichiers plats au format CSV sont utilisés avec l'édition Gouvernance.
Vous devez définir et documenter clairement chacun de ces attributs dans les formulaires d'intégration, car ils seront importés ultérieurement dans le référentiel de RAC/M Identity. Ces détails déterminent comment chaque attribut sera stocké et utilisé par la logique d'affaires pour le traitement automatisé des données.
Voir aussi
Note
Il est important d'identifier et d'intégrer toutes les sources d'identités requises dès le départ afin d'éviter l'accumulation de comptes "orphelins" qui ne peuvent être mis en correspondance avec des identités.
Identifier les actifs
Dans le contexte de RAC/M Identity, un actif, également connu sous le nom de système cible, est tout composant logique ou physique appartenant à l'organisation que les gens utilisent pour mener leurs activités et qui nécessite des privilèges d'accès.
Le terme actifs en lui-même est le terme générique utilisé pour désigner les actifs informatiques qui nécessitent que les utilisateurs se connectent pour exécuter une fonction commerciale ou technique.
Par exemple, les actifs peuvent être des applications, des systèmes d'entreprise et des composants d'infrastructure tels que la paie, l'ERP, les imprimantes, le courrier électronique, les serveurs, le réseau sans fil et même les systèmes de contrôle d'accès aux bâtiments.
Les actifs gèrent généralement les utilisateurs et ce qu'ils peuvent faire par le biais d'une base de données intégrée et dédiée contenant les comptes, les mots de passe et les droits. Les actifs peuvent s'appuyer sur des serveurs, des ordinateurs centraux ou des plateformes infonuagique. Le terme s'applique également à l'infrastructure sous-jacente telle que les serveurs, les ordinateurs centraux et les plateformes infonuagiques.
Il peut s'agir de :
- Serveurs, tels que Windows, Linux, Unix, HP UX, AIX, *NIX
- Des applications commerciales (COTS) ou maison.
- Systèmes d'entreprise, tels que les RH, les CRM, les ERP, etc.
- Bases de données
- Annuaires Active Directory
- Annuaires LDAP
- RAC/F, ACF2 ou Top Secret sur les centrales IBM
- Systèmes patrimoniaux tels que AS/400, IBM iSeries, Tandem, etc.
- Systèmes infonuagiques tels que les applications SaaS, l'infrastucture IaaS et les plateformes PaaS
- Systèmes de contrôle d'accès aux bâtiments
Applications logiques
Une application logique est un type d'actifs qui n'utilise pas une base de données intégrée pour l'authentification et l'autorisation des utilisateurs, mais qui s'appuie sur un ou plusieurs composants externes tels que des annuaires LDAP, Active Directory, des bases de données SQL, un fournisseur d'identité (IDP) ou d'autres mécanismes pour gérer l'accès des utilisateurs.
Dans ce cas, les connecteurs et les collecteurs devront être configurés pour accéder aux sources de données appropriées, telles que les annuaires LDAP ou Active Directory ou les bases de données SQL, afin d'extraire les informations d'accès qui servent à l'application logique.
Les champs de base et les attributs étendus peuvent être utilisés pour contenir des valeurs clés communes, telles que l'identifiant de l'employé ou l'adresse électronique, afin de faciliter la mise en relation d'informations provenant de sources différentes et de fournir des "vues logiques" efficaces de ces actifs.
Actifs physiques
Les biens matériels peuvent être tout article ou dispositif confié à des personnes et qui doit être suivi et récupéré à la fin de leur engagement, comme les téléphones, les outils, les vêtements spécialisés, les clés et les cartes d'accès.
Les actifs physiques n'utilisent pas de source de données pour authentifier les utilisateurs, mais une source de données peut exister pour documenter les articles détenus par chaque utilisateur. Pour chaque source, vous devez déterminer quelles sont les tables et les attributs pertinents et comment les inscrire dans RAC/M Identity.
Identifier les sources de données
Les sources de données représentent les entités réelles contenant les comptes et les informations d'accès aux actifs.
Dans le cas d'actifs tels que les systèmes RH, les applications, les répertoires, les serveurs, les bases de données et les applications et services infonuagiques, la source de données est généralement l'actif lui-même. Dans ce cas, si les informations d'accès sont accessibles directement par des API, elles peuvent être récupérés par des connecteurs, sinon elles peuvent être extraites dans un fichier plat et récupérées par des collecteurs.
Dans le cas des applications logiques, la source de données est l'annuaire, la base de données ou le fournisseur d'identité utilisé pour authentifier et autoriser les utilisateurs.
Des modèles préétablis pour les applications et systèmes les plus courants sont disponibles pour accélérer le processus d'intégration.
Note
Avec l'édition RAC/M Identity Premium, des connecteurs aux sources de données sont généralement implémentés, tandis que des collecteurs et des fichiers plats au format CSV sont utilisés avec l'édition Gouvernance, sauf pour Active Directory et ENTRA ID qui utilisent toujours un connecteur.
Conseil
Pour chaque source d'identité et actif à intégrer à RAC/M Identity, vous pouvez utiliser les formulaires d'intégration fournis pour documenter les attributs à importer. Ces détails déterminent comment chaque attribut sera stocké et utilisé par la logique d'affaires pour le traitement automatisé des données.
Identifier les propriétaires
Au sein de votre organisation, il est important d'identifier la personne qui sera responsable du bon fonctionnement et de la gestion de chaque actif critique. Cette personne est généralement appelée le "propriétaire" du bien et joue un rôle important en s'assurant que tous les accès sont légitimes.
Les propriétaires d'actifs peuvent être tenus d'approuver les demandes d'accès ainsi que d'examiner et de valider périodiquement les accès.
Note
Les actifs non critiques qui sont largement accessibles à la plupart ou à l'ensemble des utilisateurs, tels que le courrier électronique, ne nécessitent généralement pas de flux d'approbation, mais peuvent tout de même nécessiter un propriétaire chargé d'assurer une maintenance appropriée afin de maintenir l'actif pleinement fonctionnel et à jour pour limiter les vulnérabilités provenant de logiciels obsolètes ou mal configurés.
Les propriétaires peuvent désigner des délégués pour approuver les demandes afin de partager la charge de travail ou de les remplacer lorsqu'ils ne sont pas disponibles. Les délégués doivent être définis dans le groupe de délégation des propriétaires. Les propriétaires et les délégués doivent avoir une identité valide et active définie dans RAC/M Identity.
À propos des groupes de délégation
Un groupe de délégation permet à une personne de déléguer des responsabilités telles que des demandes d'approbation et des campagnes de révision d'accès. Il contient la liste des délégués auxquels des tâches peuvent être assignées et des courriels de notification envoyés.
Les groupes de délégation sont utilisés de deux manières distinctes dans RAC/M Identity et cela peut causer de la confusion car les deux se rapportent au même concept : identifier qui peut effectuer une action.
Voir aussi
Groupes de délégation pour la délégation "simple"
Il s'agit du concept original de délégation mis en œuvre dans RAC/M Identity. De nombreuses zones dans la solution permettent de définir une identité individuelle dans un champ de métadonnées (par exemple : propriétaire d'un actif, certificateur d'identité, etc.). Ceci représente l'identité responsable de l'action, mais très souvent, ils souhaitent déléguer cette responsabilité à d'autres.
Un groupe de délégation a un propriétaire représentant l'identité qui délègue sa responsabilité. La liste des membres sont les délégués à qui la responsabilité est déléguée.
Portées des groupes de délégation
La notion de portée a été ajoutée parce que la même identité pourrait vouloir déléguer certaines responsabilités à certains délégués et d'autres responsabilités à d'autres délégués. Il n'existe actuellement que deux portées définies car cette approche ne s'est pas avérée suffisamment flexible.
| Portée | Responsabilité déléguée |
|---|---|
| Générique | Toutes les responsabilités sauf celles explicitement listées dans la portée de Libre-service ou celles utilisant des groupes de travail. |
| Libre-service | Délègue le droit du propriétaire de voir les accès d'une identité pour les demandes d'accès en libre-service (lors de l'utilisation de la fonction "filtrer les accès par identité") ou les demandes de suppression d'accès. Le propriétaire a ce droit pour toutes les identités dont il est l'approbateur. |
Confusion des groupes de délégation
Évitez de créer plus d'un groupe de délégation avec un propriétaire donné dans une portée donnée. Dans cette situation, RAC/M Identity décide arbitrairement quel groupe utiliser pour déléguer une responsabilité et cela peut causer de la confusion.
Groupes de délégation en tant que groupes de travail
Cette façon d'utiliser les groupes de délégation a été introduite pour résoudre le problème de flexibilité des groupes de délégation "simples". Dans cette approche, une responsabilité spécifique est explicitement déléguée à un groupe de délégation. Les champs de métadonnées sur un objet qui déterminent qui est responsable sélectionnent un groupe de délégation au lieu d'une identité individuelle. Tous les champs récemment ajoutés utilisent cette approche pour offrir une plus grande flexibilité.
Cette approche ignore complètement la portée car le groupe de délégation est explicitement défini.
Types de groupes de délégation
Le type de groupe de délégation détermine comment les délégués seront informés de la responsabilité déléguée.
| Type | Mécanisme de délégation |
|---|---|
| CASCADE_GROUP | Les membres du groupe de délégation sont notifiés selon leur priorité. La priorité est en fait le nombre de rappels (à partir de 1) avant qu'un membre ne soit notifié de la tâche. Notez que le membre peut effectuer la tâche dès qu'elle est créée, même avant qu'il ne reçoive la notification selon sa priorité. Pour des raisons historiques, les propriétaires ne sont jamais notifiés de la tâche, mais ils devraient l'être en utilisant ce type de groupe. Ceci pourrait être modifié dans une future version. |
| CASCADE_GROUP_EXCL_OWNER | Ne pas utiliser. Réservé pour une utilisation future. |
| SIMPLE_GROUP | Tous les membres du groupe de délégation et le propriétaire seront informés dès qu'une tâche est créée. La priorité des membres est ignorée. |
| SIMPLE_GROUP_EXCL_OWNER | Tous les membres du groupe de délégation seront notifiés dès qu'une tâche est créée. Le propriétaire ne sera pas averti à moins qu'il ne soit explicitement membre du groupe en plus d'être le propriétaire. |
À propos des flux d'approbation (édition Premium)
Des flux d'approbation peuvent être définis pour chaque actif critique et chaque droit. Les flux d'approbation sont invoqués lorsqu'une demande d'accès est effectuée par le portail en libre-service ou par d'autres moyens.
RAC/M Identity comprend une fonction de flux de travail flexible qui vous permet de composer des flux de travail pour répondre à vos besoins spécifiques sans avoir à recourir à des flux de travail personnalisés ou à écrire du code.
Les flux d'approbation peuvent avoir jusqu'à trois niveaux et vous devez déterminer combien de niveaux sont nécessaires et qui doit approuver la demande en fonction de la criticité du bien et de l'accès demandé.
Les niveaux sont additifs, ce qui signifie que certains biens peuvent ne nécessiter que l'approbation du gestionnaire du demandeur, tandis que d'autres peuvent nécessiter des étapes d'approbation supplémentaires par le propriétaire du bien et même des biens plus critiques peuvent nécessiter une troisième étape d'approbation par des approbateurs spéciaux.
Les trois niveaux d'approbation communs sont les suivants :
Approbation par le responsable du demandeur ou ses délégués. Ce niveau peut être suffisant pour les biens qui sont modérément critiques.
Approbation par le propriétaire de l'actif, un approbateur spécifique ou leurs délégués. Ce niveau est généralement utilisé pour les systèmes critiques et les systèmes financiers pertinents dans le contexte de Sarbanes-Oxley, SOC 2, NERC, NIST, ISO ou d'autres cadres de contrôle de gestion ou de sécurité.
Approbation par un approbateur spécial ou ses délégués. Ce niveau n'est généralement utilisé que pour les biens hautement critiques qui nécessitent une approbation spéciale.
Il existe un niveau d'approbation supplémentaire pour les modifications de rôles. Si l'approbation globale est configurée, ce niveau permet d'aller chercher l'approbation par des administrateurs à des fins de validations et de la gestion des options d'activations.
Note
Les actifs non critiques qui sont largement accessibles à la plupart ou à tous les utilisateurs, comme le courrier électronique, ne nécessitent généralement pas de flux d'approbation.
Voir aussi
À propos de la structure organisationnelle
L'organisation et le département pour lesquels une personne travaille font partie de la description de l'identité de la personne dans RAC/M.
La définition de la structure de votre organisation permet à RAC/M Identity de prendre en charge une automatisation accrue des processus et d'appliquer la gouvernance par le biais de règles d'affaires.
Vous pouvez définir la structure de votre organisation en décrivant les départements et divisions de votre organisation, la personne responsable de chaque niveau, ainsi que d'autres informations complémentaires telles que la localisation, les centres de coûts, etc.
Si certains éléments structurels ne sont pas uniques (par exemple, un service de cardiologie), vous pouvez créer une clé unique pour cet élément en concaténant les informations de différents champs trouvés dans les colonnes de la base de données du référentiel (reportez-vous à la section Construire des clés à partir de plusieurs colonnes).
Note
Étant donné que les demandes d'accès peuvent nécessiter l'approbation du responsable du demandeur, il est important d'identifier les responsables et les superviseurs dans chaque département et division de votre organisation. Cela permet à la logique d'affaires de déterminer automatiquement qui peut être contacté pour approuver les demandes ou réviser les accès.
RAC/M Identity dispose de trois éléments structurels avec lesquels il est possible de travailler, et de multiples niveaux d'organisations et de départements peuvent être ajoutés pour correspondre à votre organisation. Les éléments structurels sont les suivants :
- Entreprise : Cet élément structurel se trouve au sommet de la hiérarchie. Il correspond au niveau le plus élevé de votre organisation dans son ensemble.
- Organisation : Il s'agit d'une sous-catégorie de l'entreprise. Elle peut correspondre aux divisions d'une entreprise, aux différents campus d'une université, aux différents hôpitaux d'un même réseau de santé.
- Département : Il s'agit d'une sous-catégorie de l'organisation. Elle pourrait correspondre aux différents départements des divisions d'une entreprise, aux différents départements d'une université, etc. Dans l'Exemple d'une structure organisationnelle dans RAC/M Identity, elle correspond aux départements ou unités de l'hôpital.
Dans RAC/M Identity, la Structure organisationnelle se trouve dans la barre de menu sous ORGANISATION> Structure.
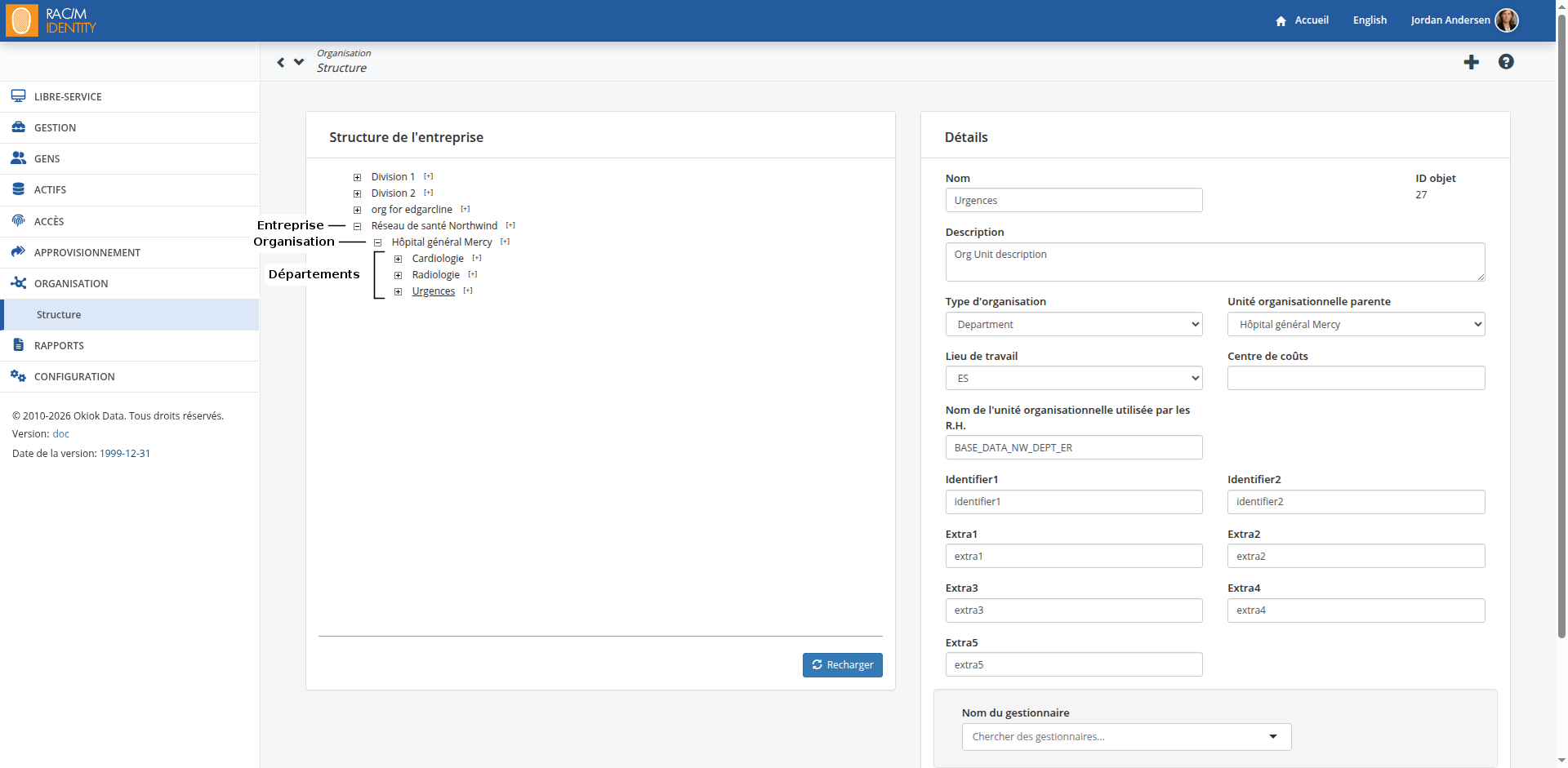
Bien que vous puissiez créer et modifier l'organigramme manuellement, il est généralement importé automatiquement via une séquence.
Lorsque vous ouvrez la page, seule l'entreprise est affichée. Pour développer l'arbre, cliquez sur le signe plus à gauche des différents éléments de la structure. Lorsque vous sélectionnez un élément de la structure, ses détails apparaissent sur la droite.
Note
Bien que vous puissiez modifier les informations directement dans cette page, les modifications pourraient être perdues lorsque la structure sera mise à jour via une séquence.
Identifier la structure de travail
Chaque organisation a généralement sa propre nomenclature pour désigner sa structure de travail interne pour les emplois, les responsabilités, les autorisations et le statut d'emploi.
RAC/M Identity peut utiliser cette nomenclature pour étiqueter correctement les objets liés ainsi que pour prédéfinir des statuts normalisés afin de refléter diverses situations telles que le statut professionnel. Voici des exemples de termes qui peuvent faire partie d'une structure de travail :
- Départements
- Unités organisationnelles (OU)
- Centres de coûts
- Sites
- Locations
- Étages
- Services
- Titres d'emploi
- Niveaux de rémunération
- Responsabilités
- Nomenclature des statuts d'emploi (par exemple, temporaire, contractuel, invalidité de longue durée, vacances, congé d'invalidité, etc.)
Conseil
Il est recommandé de documenter et d'organiser la structure de travail et la terminologie à utiliser dans les processus GIA améliorés. Cela permettra d'assurer une utilisation cohérente et harmonisée des termes représentant les statuts, les niveaux hiérarchiques, etc., ce qui améliorera considérablement la qualité du résultat.
Voir aussi
À propos des attributs étendus
Les attributs étendus permettent au modèle de données des principaux objets de RAC/M Identity d'être facilement étendus à tout moment pour contenir des attributs pertinents pour votre organisation.
Par exemple, si une formation spécifique est requise pour accéder à certaines applications, un attribut étendu peut être ajouté à l'objet Identity pour contenir les certifications détenues par la personne.
La logique d'affaires peut vérifier si les exigences sont satisfaites en contrôlant ces attributs étendus avant d'attribuer des rôles ou d'accorder des droits.
Les attributs étendus sont créés via la console de gestion et stockés dans des tables secondaires liées aux tables principales représentant les objets à étendre.
Ajouter des attributs étendus
Pour ajouter des attributs étendus aux objets RAC/M.
- Dans la barre de menu, cliquez sur CONFIGURATION> Mappings.
- Sélectionnez l'onglet Attributs étendus.
- Sélectionnez l'objet pour lequel vous souhaitez visualiser, modifier ou ajouter des attributs étendus.
- En haut de la page, cliquez sur le bouton
 .
. - Dans les champs Nom d'affichage et Description, entrez un nom qui reflète la signification de l'attribut étendu et une courte description qui sera affichée sous le nom de l'attribut.
- Dans le champ Nom technique, saisissez un nom court et unique qui sera utilisé comme référence interne au nouvel attribut étendu.
- Cochez les cases appropriées si la nouvelle valeur de l'attribut doit être unique et si la valeur de l'attribut peut être modifiée depuis la console de gestion. Si elle n'est pas modifiable depuis la console, la valeur ne peut être définie qu'au moment de l'importation ou modifiée à l'aide de la logique d'affaires.
À propos des hiérarchies de groupes et de rôles
Pour faciliter la gestion des droits et des droits effectifs, RAC/M Identity met en œuvre un modèle hiérarchique où les groupes et les rôles parents incluent les droits et les droits d'accès des groupes et des rôles enfants.
Ainsi, dans RAC/M Identity, un groupe de sécurité tel que Propriétaires de produit inclurait le groupe Membres d'équipe, qui inclut le groupe Employés, fournissant ainsi aux membres du groupe Propriétaires de produit les droits d'accès et les autorisations agrégés des groupes Propriétaires du produit, Membres d'équipe et Employés.
Il en va de même pour les rôles. Puisque, dans RAC/M Identity, les rôles peuvent inclure d'autres rôles, les identités qui sont membres du rôle Propriétaires de produit qui inclut les rôles Membres d'équipe et Employés, se verront accorder les droits d'accès et les autorisations associés aux rôles Propriétaires de produit, Membres d'équipe et Employés.

Bien que la représentation de la hiérarchie diffère, le résultat final est le même. Les droits effectifs détenus par les utilisateurs sont exactement les mêmes dans les deux représentations.
Important
La notion d'inclusion est l'inverse d'un modèle d'héritage tel qu'il est mis en œuvre dans Active Directory mais s'aligne sur d'autres grands systèmes tels que SAP.
Cela signifie que, lors de l'importation de groupes de sécurité depuis Active Directory et Entra ID, les groupes qui sont membres d'autres groupes doivent être importés comme parents de ces autres groupes.
À propos de l'analyse des données
Cette section décrit comment analyser les sources d'identités et de données pour préparer l'importation de données via des collecteurs et des connecteurs.
Note
Pour plus d'informations sur la façon d'identifier les sources d'identités et les sources de données, reportez-vous à Identifier les sources d'identités et Identifier les sources de données.
Avant de commencer à importer des données, vous devez les examiner pour vous assurer qu'elles sont propres et cohérentes, et qu'elles contiennent les informations dont vous avez besoin.
Si certains éléments des données ne sont pas clairs, incohérents ou de mauvaise qualité, vous devez contacter la personne responsable de cette source de données et tenter de résoudre les problèmes avant de tenter d'importer des données. La cohérence et la qualité des données sont extrêmement importantes pour construire et maintenir un référentiel efficace et fiable.
Conseil
Prêtez une attention particulière aux noms et aux dates. Les gens utilisent souvent des formes différentes de leur nom. Cela rend difficile la correspondance des comptes à la bonne identité et à la bonne personne. RAC/M Identity comprend plusieurs mécanismes puissants pour faire correspondre automatiquement les comptes aux identités, mais l'utilisation de noms cohérents à travers les différentes applications, les systèmes et les applications réduit considérablement le temps et les efforts nécessaires pour obtenir une correspondance complète.
Il faut également prêter une attention particulière aux dates qui peuvent être stockées sous différents formats. Il est important que les dates stockées dans un système RH ou une application utilisent un format cohérent. RAC/M Identity tentera de reconnaître le format de la date, mais la cohérence réduit la probabilité d'erreurs.
Note
Il est important de comprendre que toutes les intégrations sont différentes et que vous pouvez rencontrer des situations et des problèmes différents d'une intégration à l'autre. Bien que ce guide donne un aperçu de l'analyse que vous devez effectuer et des types de problèmes que vous pouvez rencontrer, il ne peut pas couvrir toutes les situations possibles.
Déterminer des identifiants uniques
Chaque objet RAC/M Identity doit avoir un identifiant unique pour le distinguer des autres objets. Cet identifiant unique est la clé unique qui doit être construite à partir des éléments de données disponibles.
Par exemple, sur la base de cette clé unique, lors de l'importation de données d'identité, RAC/M Identity sera capable de déterminer si une identité existe déjà et doit seulement être mise à jour ou si une nouvelle identité doit être créée.
En outre, RAC/M Identity attribue à chaque personne et à chaque identité un identifiant unique permanent généré par le système : un UUID (Universally Unique Identifier), aussi appelé GUID (Globally Unique Identifier). Ces valeurs sont distinctes de la clé primaire que vous configurez à partir des attributs sources ; elles distinguent durablement chaque enregistrement du référentiel les uns des autres et évitent toute ambiguïté lorsque les noms ou d'autres données évoluent.
Clé primaire
La clé unique associée aux objets de RAC/M Identity est appelée clé primaire. C'est la première chose que vous devez déterminer lorsque vous intégrez un système source ou cible d'identité. Déterminer une clé primaire peut être un défi, surtout lorsque les politiques ou les règlements interdisent l'utilisation d'informations sensibles telles que le numéro d'assurance sociale (NAS), la date de naissance, etc.
L'idéal est d'utiliser un code permanent et unique, tel qu'un numéro d'employé ou d'étudiant ou une adresse courriel.
Si une clé primaire évidente ne peut être trouvée, vous devez rencontrer l'expert de domaine responsable du système source ou cible de l'identité et déterminer quels attributs ou combinaison d'attributs peuvent être utilisés comme clé primaire.
Plusieurs attributs peuvent être concaténés pour construire une clé unique. Voir Construire des clés à partir de plusieurs colonnes
Clés externes
Les clés externes sont définies pour établir des liens avec des tables secondaires, telles que la table Employment_Status (liste des statuts d'emploi de l'organisation) ou la table Employment_Type (liste des types d'emploi de l'organisation). Ces tables secondaires mettent en correspondance des données primaires comme les personnes, les identités, les applications, les rôles, etc. avec des données secondaires qui peuvent prendre plusieurs valeurs distinctes.
Exemple
Bien qu'il puisse y avoir 1,000 identités dans la base de données, chacune d'entre elles pouvant avoir l'un des quatre statuts d'emploi différents, tels que actif, inactif, retraité et congé maladie, la table *Statut_de_l'emploi contiendrait alors ces 4 statuts. Les identités obtiendraient alors leur statut en se liant à cette table via une clé externe.
Dans RAC/M Identity, les clés externes sont identifiées par les préfixes HR_, RH_, EXT_ ou le suffixe _ID.
Note
Pour plus d'informations sur les clés externes utilisées lors de l'importation de sources de se reporter à La table IDENTITY_IMPORT et La table STRUCTURAL_IMPORT.
Vous devez donc vous assurer qu'il existe des attributs dans les colonnes du fichier source qui peuvent être utilisés comme clés externes.
Construire des clés à partir de plusieurs colonnes
S'il n'est pas possible de trouver une clé unique dans une seule colonne, RAC/M Identity vous permet de concaténer des colonnes afin de créer un identifiant unique.
Exemple
Un réseau hospitalier compte 2 hôpitaux : l'hôpital St. Mary et l'hôpital général, chacun avec les mêmes départements. Les noms des départements ne peuvent pas être utilisés comme clé unique pour se référer à chaque département car ils apparaissent plus d'une fois et ne sont donc pas uniques. Vous pouvez créer une clé unique en combinant le nom de l'hôpital et le nom du service : "St. Mary - Cardiologie" et "Hôpital général - Cardiologie".
Cette combinaison devient alors une clé que vous pouvez utiliser pour identifier de manière unique chaque service.
Pour plus d'informations sur la concaténation, voir Configurer un collecteur.
La situation inverse peut également se produire. Des parties d'informations dans une colonne peuvent être requises pour deux clés distinctes. Dans ce cas, vous devez reformater le fichier pour diviser le contenu de la colonne source en deux colonnes. (voir Configurer un formateur).
Exemple
La source d'identité affiche le nom complet (prénom et nom) des personnes dans une seule colonne au lieu de deux. Dans ce cas, vous devrez reformater le fichier et générer deux colonnes, à partir d'une seule, afin de remplir les colonnes Nom_complet et Nom_de_famille dans RAC/M.
À propos de logique d'affaires et de traitement des données
Dans cette section, vous apprendrez les concepts relatifs à la réalisation de la logique d'affaires et à la définition des séquences de traitement dans RAC/M Identity par simple configuration, sans avoir recours à la programmation ou au scriptage. C'est l'approche No-Code/Low-Code.
Le terme "logique d'affaires" fait référence aux instructions qui déterminent comment les données sont créées, stockées et traitées.
Une fois que vous avez identifié vos sources d'identités et de données, analysé leur contenu et compris quelles données vous devrez importer dans les tables cibles appropriées, vous devez décider comment vous allez traiter ces données : Dans quel ordre allez-vous importer les données depuis les tables d'import ? Devez-vous normaliser certaines des données avant de les importer ? RAC/M Identity doit-il marquer certaines identités lors du traitement des données ?
Ce sont quelques-unes des questions que vous devrez vous poser pour vous assurer que RAC/M Identity traite les données de manière à optimiser votre système de gestion des identités et des accès (GIA).
RAC/M Identity offre un large éventail de possibilités pour améliorer, corréler et traiter les données trouvées dans les sources d'identités et les sources de données. Par exemple, dans RAC/M Identity, la logique d'affaires peut être définie pour :
- Assurer le traitement ordonné des données actualisées provenant des sources d'identités et des sources de données;
- Consolider, harmoniser et assurer l'intégrité des attributs sur plusieurs sources d'identités et systèmes cibles;
- Valider et assurer la qualité du référentiel;
- Déclencher des événements et initier des réponses telles que l'envoi de rapports et de notifications par courriel;
- Initier des actions pour demander, assigner ou révoquer des droits.
Note
L'optimisation des processus nécessite plusieurs itérations au cours desquelles la logique d'affaires est affinée en tenant compte de l'évolution de la qualité des données ainsi que de la maturité évolutive des processus GIA de support.
Dans RAC/M Identity, la logique d'affaires permettant de traiter les données est mise en œuvre via des modules, des blocs et des séquences.
Les formateurs, les collecteurs, les gestionnaires de fichiers et les modules peuvent être utilisés tels quels. Ces objets prêts à l'emploi ainsi que les centaines de primitives disponibles sont décrites dans le document RAC/M Identity - Guide de référence technique.
Si vous ne trouvez pas le module exact dont vous avez besoin, vous pouvez en dupliquer un et le modifier pour l'adapter à vos besoins, ou même en construire un à partir de zéro, directement dans RAC/M Identity. Chaque élément de la logique d'affaires est mis en œuvre par le biais d'un module, qui est une fonction de base utilisée pour manipuler les données dans le référentiel. Les modules peuvent être représentés comme le plus petit traitement qui peut être effectué sur les données et sont donc généralement dédiés à un but unique et spécifique.
Le module le plus couramment utilisé est celui qui prend les données de la table d'import et les normalise pour qu'elles correspondent à la façon dont les informations sont affichées dans RAC/M.
Exemple
Pour transférer les données de la table de transit IDENTITY_IMPORT vers la table cible Identification, vous devez créer un module qui utilise la primitive ModuleCopyColumnsAndInsert.
Bien que le terme "module" désigne la forme générique de logique d'affaires, il comprend aussi, au sens large, des types de logique d'affaires spécialisés:
- Gestionnaires de fichiers
- Formateurs
- Collecteurs
- Connecteurs ICF
- Modules de traitement
- Extracteurs

Les paragraphes suivants présentent les objets que vous utiliserez pour traiter les données.
Gestionnaires de fichiers
Les gestionnaires de fichiers vous permettent de connecter RAC/M Identity à des serveurs, tels que des sites FTP, qui contiennent les répertoires qui hébergent les données qui vous intéressent. Pour plus d'informations, voir Configurer un gestionnaire de fichiers.
Formateurs
Les formateurs vous permettent de pré traiter les données, afin de les structurer de façon compatible avec RAC/M Identity. Par exemple, ils peuvent être utilisés pour séparer le "prénom" et le "nom" d'une identité si la source ne possède que la colonne "nom complet". Pour plus d'informations, voir Configurer un formateur.
Connecteurs ICF
Les connecteurs ICF vous permettent de connecter RAC/M Identity directement à des sources de données, telles qu'Active Directory, ENTRA ID ou autres. Pour plus d'informations, voir Connecteurs ICF.
Collecteurs
Les collecteurs vous permettent d'importer des données extraites d'un fichier plat, tel qu'un fichier CSV et lorsque les données sont importées via un connecteur ICF ou un gestionnaire de fichier afin de les placer dans les tables d'import RAC/M Identity. Pour plus d'informations, voir Configurer un collecteur.
Les collecteurs contrôlent la façon dont les attributs des sources autoritaires sont mappés au référentiel. Vous pouvez choisir quels attributs mapper, appliquer des transformations telles que la définition de valeurs constantes, et préciser quelle source a la priorité de mise à jour (ou autorité) sur chaque attribut.
Détermination de la priorité des attributs
Configurer un mappage d'attribut dans un collecteur fait de ce collecteur une source autoritaire pour les attributs concernés. Lorsqu'un même attribut est alimenté par plusieurs collecteurs, la valeur finale conservée dans le référentiel est déterminée par l'ordre d'exécution des collecteurs au sein des blocs et séquences parents : la dernière valeur écrite prévaut.
Modules Génériques
Les modules génériques sont construits afin de constituer la logique d'affaires requise pour traiter les données de votre organisation (voir À propos des modules). Ils peuvent être utilisés pour copier des données de la table d'import vers le référentiel d'identités et d'accès, pour normaliser des données, pour trouver des données non fiables, four envoyer des courriels de notification et pour effectuer tout autre traitement requis. Pour plus d'informations, voir Configurer un module.
Extracteurs
Les extracteurs vous permettent d'extraire des données du référentiel d'identités et de les déposer dans un format standard, tel qu'un fichier CSV. Pour plus d'informations, voir Configurer un extracteur.
Les données extraites du référentiel sous forme de fichier CSV peuvent être transférées vers des systèmes externes tels que des solutions SIEM au moyen des mécanismes ou API disponibles, via la logique d'affaires configurable.
Blocs
Un bloc est un groupe de modules requis pour effectuer une tâche spécifique. Lorsque les processus nécessitent plusieurs modules pour effectuer une tâche donnée, ceux-ci peuvent être regroupés et organisés en blocs. Pour plus d'informations, voir Configurer un bloc.
Exemple
Pour mettre à jour les identités dans le référentiel, vous utiliserez un module qui efface les données, suivi d'un autre module qui importe la structure, suivi d'un autre qui importe la hiérarchie, etc.
Comme pour les modules, les blocs peuvent être assemblés pour exécuter des tâches plus élaborées. Les assemblages de blocs sont appelés séquences.
Séquences
Les séquences sont une collection de blocs qui sont exécutés pour accomplir un processus spécifique.
Les séquences sont constituées à partir d'un ou plusieurs blocs et sont utilisées afin d'effectuer l'ensemble des étapes requises pour compléter une tâche spécifique comme importer les données, détecter les arrivées,les départs et les déplacements et effectuer les modifications d'accès requises. Pour plus d'informations, voir Configurer une séquence.
Exemple
Pour mettre à jour à la fois les identités et les comptes dans le référentiel, vous pouvez utiliser un bloc qui met à jour les identités et un autre qui met à jour les comptes et inclure les deux blocs dans une seule séquence.
Les séquences peuvent être lancées manuellement ou automatiquement en fonction d'une planification que vous définissez. Ce type de planification peut être utilisé pour garantir que le référentiel est toujours à jour avec les sources d'identités et de données.
Habituellement, la première séquence dont vous aurez besoin ne contiendra qu'un seul bloc composé du collecteur et du gestionnaire de fichiers qui vous permettront d'importer des données à partir de votre sélection de sources d'identités et de données, et des modules permettant de copier les informations dans le référentiel.
Cela vous permettra de jeter un premier coup d'œil aux données, de confirmer que tout est correctement importé et de commencer à peaufiner la logique d'affaires.
Modules personalisés
Dans certains cas, il faut effectuer des traitements ou des actions spécifiques qui ne peuvent être réalisés à l'aide des objets préconstruits, en construisant des objets à partir de zéro ou en modifiant des objets existants.
Dans ce cas rare, des modules personnalisés peuvent être développés à l'aide de modules de scripting ou en Java et invoqués dans le cadre d'une séquence comme tout autre objet.
Ces petits modules personnalisés peuvent implémenter n'importe quelle logique d'affaires, supprimant ainsi toute limite ou contrainte technologique. Ces modules personnalisés peuvent être développés par vous ou par OKIOK.
Note
Une formation sur le SDK RAC/M Identity et les sujets d'intégration avancés ainsi que des compétences en SQL et en développement Java sont recommandées pour développer avec succès des modules personnalisés.
Les modules personnalisés sont déployés séparément de la distribution de base RAC/M Identity. Ceci afin de préserver la personnalisation spécifique tout en permettant à la distribution de base d'évoluer et d'être mise à jour lorsque de nouvelles versions sont disponibles.
Répondre aux événements déclencheurs
Événements déclencheurs est un terme utilisé pour décrire les situations qui, lorsqu'elles sont détectées par RAC/M Identity, entraînent le déclenchement d'une ou plusieurs actions automatisées.
Voici quelques exemples d'événements déclencheurs :
- Détecter que des personnes ont quitté l'organisation et que leurs comptes doivent être supprimés de tous les systèmes et applications qu'elles utilisaient.
- Détecter que de nouvelles personnes ont rejoint l'organisation et qu'un "bloc d'accès de base" doit être créé pour elles. (Ce bloc d'accès de base comprend généralement la création d'un compte dans Active Directory, l'ajout du compte à quelques groupes de base et la création d'un compte de messagerie et d'une boîte aux lettres).
- Recevoir des demandes pour ajouter de nouveaux accès ou rôles, ou pour modifier ou révoquer ceux qui existent déjà.
- Détecter les modifications au contenu des rôles ou des attributions de droits d'accès qui entraînent des changements devant être propagés aux systèmes cibles.
- Détecter des modifications aux attributs dans les sources d'identités qui signalent un changement de statut d'emploi ou une mutation qui entraînent des changements d'accès devant être propagés aux systèmes cibles.
- Tout événement ou situation qui nécessiterait en fin de compte une notification ou une action à entreprendre.
En général, ces événements déclencheurs sont détectés par des modules dans des séquences qui sont exécutées automatiquement à une fréquence prédéterminée. Par exemple, la détection des arrivées et des départs est généralement effectuée quotidiennement, ou plus fréquemment, afin de pouvoir rapidement créer ou révoquer les accès.
Veuillez vous reporter à la publication RAC/M Identity - Guide de référence technique pour plus d'informations sur les modules intégrés qui peuvent être utilisés pour détecter ces événements déclencheurs.
Une fois qu'un événement déclencheur est détecté, la logique d'affaires invoquée peut effectuer tout genre de traitement, comme par exemple, la génération et la distribution d'un courriel qui énumère tous les comptes à supprimer de divers systèmes et applications lorsqu'une personne quitte l'entreprise ou la création d'un billet contenant toutes les informations pertinentes dans un système de billetterie comme ServiceNow, Jira ou autre.
Une autre réponse courante aux événements déclencheurs est le provisionnement ou le déprovisionnement des comptes et des accès. Lorsque les sources de données et les applications sont intégrées à l'aide de connecteurs bidirectionnels, le provisionnement et le déprovisionnement peuvent être entièrement automatisés.
Générer un courriel de demande
La réponse la plus simple, consiste à générer un courriel qui est envoyé à un service d'assistance pour demander la création, la modification ou la suppression de comptes et d'accès.
RAC/M Identity fournit des modèles de courriel que vous pouvez facilement personnaliser pour qu'ils correspondent à l'apparence de votre organisation en ajoutant vos logos, vos coordonnées et votre terminologie.
En outre, la logique d'affaires du module générant le courriel de réponse peut acheminer le courriel vers plusieurs centres de service en fonction des sources de données ou des applications, ou de toute autre considération.
Il est possible d'insérer des balises dans l'objet et le corps du courriel, qui seront remplacées par les données réelles du référentiel lorsque le courriel sera généré.
Il est également possible d'envoyer un courriel structuré à un système de billetterie (ITSM) plutôt qu'à un service d'assistance.
Le courriel structuré est construit de la même manière que celle décrite ci-dessus, mais des champs et un format spécifiques peuvent être requis dans l'objet ou le corps de courriel afin que le système de billetterie puisse extraire les informations nécessaires pour générer le billet.
Créer un billet dans un système de billetterie
Une alternative à l'envoi d'un courriel est l'ouverture d'un billet de service dans une solution ITSM comme ServiceNow, Jira, C2, etc. Cette approche permet de récupérer le numéro de billet qui est automatiquement inscrit dans les artefacts de suivi gérés par RAC/M Identity, ce qui assure la traçabilité des actions prises.
De plus, ces billets peuvent être mis à jour pour refléter l'évolution de la requête jusqu'à la fin des traitements qui en découlent.
RAC/M Identity permet d'associer des systèmes de billetterie en fonction des sources de données ou des applications visées, ou de toute autre considération.
Approvisionnement et déprovisionnement automatisé
En général, il faut un certain temps à une organisation pour atteindre le niveau de maturité nécessaire à la mise en œuvre de l'approvisionnement et du désaprovisionnement automatisés. La raison en est que l'approvisionnement des comptes pour les systèmes et les applications est complexe et que de nombreuses décisions doivent être prises pour créer un compte et attribuer les bons niveaux de privilèges.
Les systèmes automatisés, contrairement aux humains, ne peuvent pas prendre de telles décisions. Plusieurs considérations doivent être analysées et résolues à l'avance, telles que:
- L'emplacement dans l'arborescence du répertoire
- La nomenclature du compte
- La nomenclature des mots de passe
- La gestion des collisions
- L'appartenance à un groupe / profil
- Le traitement des défaillances techniques
RAC/M Identity vous permet de définir des politiques et une nomenclature de comptes et de mots de passe conformes aux politiques de sécurité et de gestion des accès de votre organisation.
Il est également important de décider où les comptes doivent être créés ou où ils doivent être déplacés lorsqu'un accès est révoqué. En général, il est recommandé de ne pas supprimer les comptes des répertoires ou des systèmes mais de les mettre dans un état inactif et de les déplacer vers une unité organisationnelle (OU) spécifique. Cela facilite grandement l'application d'une politique de "non-réutilisation" des comptes.
Voir aussi
Notification d'approvisionnement
Lorsque des accès sont approvisionnés automatiquement suite à une demande, les personnes suivantes peuvent être notifiées :
- Le demandeur (la personne ayant fait la demande)
- La cible (la personne recevant les accès)
- Le superviseur de la cible
- Les membres du groupe de notification d'approvisionnement de la cible
L'envoi de ces notifications peut être configurée pour chaque regroupement d'actifs, actif et groupe. Pour accéder à cette configuration, il suffit de se rendre sur la page d'un regroupement d'actifs, d'un actif ou d'un groupe. La sélection se trouve sous le panneau "Approvisionnement" ou "Notification d'approvisionnement", selon le cas.
Il existe une hiérarchie dans la configuration des notifications. La configuration au niveau du regroupement d'actifs peut s'appliquer à tous les actifs et groupes qu'il contient. De même, la configuration au niveau de l'actif peut s'appliquer à tous les groupes qu'il contient. Alternativement, une configuration spécifique à un actif ou à un groupe permet de définir plus précisément le comportement souhaité pour chacun de ces éléments.
La configuration de la notification d'approvisionnement permet de spécifier les options de notification pour les comptes, les accès et les mots de passe, et ce, pour chacun des destinataires possibles. Les options disponibles sont les suivantes :
| Option | Description |
|---|---|
| Lors de la création ou de l'activation d'un compte | Cette option permet d'envoyer une notification pour les comptes qui sont créés ou activés. |
| Lors de la modification des accès | Cette option permet d'envoyer une notification pour les accès qui sont approvisionnés. Lorsqu'elle est sélectionnée, elle entraîne également l'inclusion des comptes qui sont associés à ces accès. |
| Lors d'un changement de mot de passe | Cette option permet d'envoyer une notification pour les nouveaux mots de passe. Il s'agit généralement de mots de passe pour des comptes qui viennent d'être créés. Lorsqu'elle est sélectionnée, elle entraîne également l'inclusion des comptes associés à ces mots de passe, sauf si l'option d'envoi du mot de passe dans un courriel séparé est sélectionnée. |
| Envoyer le mot de passe dans un courriel séparé | Cette option permet d'envoyer le mot de passe dans un courriel séparé de celui contenant le nom du compte. |
Ces options sont disponibles pour chaque destinataire, sauf l'option d'envoyer le mot de passe dans un courriel séparé, qui est une option globale.
La flexibilité de ces options permet de répondre à des besoins spécifiques. Il est possible, par exemple, d'envoyer une notification de création de compte au demandeur, à la cible et et au superviseur de la cible, une notification incluant les accès seulement au demandeur et à la cible, et le mot de passe uniquement à la cible.
Il est également possible de spécifier une configuration particulière pour un groupe. Cette configuration a priorité sur celle de l'actif et du regroupement d'actifs. Par exemple, un groupe à bas privilèges qui générerait un grand nombre de courriels pourrait avoir comme configuration de n'envoyer aucune notification. À l'inverse, un groupe qui revêt une importance particulière pourrait être configuré pour que des personnes spécifiques soit notifiées dès qu'un compte est approvisionné dans celui-ci.
À propos de l'importation des données dans le référentiel
Ce chapitre décrit comment importer des données dans le référentiel de RAC/M Identity.
L'importation des données se fait en important les informations extraites d'une source de données dans un fichier plat au format CSV, ou en utilisant un connecteur pour importer directement depuis une source de données telle que Active Directory.
Dans les deux cas, des collecteurs sont utilisés pour faire correspondre les données, qui se trouvent soit dans les colonnes des fichiers plats, soit dans les attributs des systèmes sources, aux colonnes des tables d'import de RAC/M Identity.
Tables d'import
Lorsque vous importez des données, elles sont placées dans des tables d'import du référentiel, qui sont des tables dans lesquelles vous pouvez importer, nettoyer, formater et prétraiter les données avant de les copier dans le référentiel de RAC/M Identity.
Cela permet d'assurer une qualité optimale des données en appliquant une logique d'affaires et des règles de validation avant de les introduire dans le référentiel.
Les tables d'import sont les tables cibles que vous sélectionnez lorsque vous importez des données via des collecteurs et des connecteurs.
De même, ce sont les tables sources que vous sélectionnez lorsque vous copiez des données dans des tables secondaires ou dans le référentiel lui-même via des modules.
Note
Le référentiel d'identités RAC/M est vaste. Au fil du temps, vous vous familiariserez avec l'ensemble de ses tables et attributs. Mais pour l'instant, il est seulement important que vous vous familiarisiez avec les objets essentiels requis pour commencer.
Description des tables d'import
La section suivante fournit une description détaillée des principales tables d'import disponibles.
Les noms des tables d'import utilisent le suffixe "_IMPORT".
Les principales tables d'import sont :
- IDENTITY_IMPORT : Pour l'importation des informations d'identité
- STRUCTURAL_IMPORT : Pour l'importation de votre structure organisationnelle
- APPLICATION_ACCOUNT_IMPORT : Pour importer des comptes et des groupes d'actifs
- PROFILE_HIERARCHY_IMPORT : Pour importer des groupes et des descriptions à partir d'actifs
Les descriptions présentées ci-dessous ont pour but de vous aider à déterminer quels champs des sources de données correspondent le mieux aux champs de données des tables d'import, afin qu'ils puissent être mappés correctement pendant l'importation des données.
N'oubliez pas non plus que des traitements peuvent être effectués sur les données lors de l'importation à l'aide de collecteurs et de connecteurs pour les compléter et les améliorer. Par exemple, des opérations telles que l'affectation de valeurs constantes, la concaténation de données et bien d'autres sont disponibles.
L'application des opérateurs de données aux collecteurs et aux connecteurs est abordée en détails dans une section ultérieure.
Note
Des champs de données supplémentaires à ceux décrits peuvent être importés dans les champs extra présents dans chaque table d'import. Ces champs peuvent contenir toute donnée utile et pertinente pour votre organisation. L'importation d'informations supplémentaires est un sujet avancé et est abordé plus en détails dans une section ultérieure. Vous pouvez également communiquer avec OKIOK pour discuter de votre stratégie d'intégration avec nos experts en matière de GIA.
Voir aussi
La table IDENTITY_IMPORT
La table IDENTITY_IMPORT est l'endroit où les données de vos sources d'identités sont importées. Elle vous permet de définir des identités dans RAC/M et de renseigner des tables secondaires, telles que la table Employment_Status (qui répertorie tous les statuts d'emploi de votre organisation) et la table Employment_Type (qui répertorie tous les types d'emploi de votre organisation).
Les données sont importées dans cette table à l'aide du collecteur IdentitiesImport (voir Configurer un collecteur) ou d'un connecteur approprié tel que l'un des connecteurs RH.
Les principaux attributs sont énumérés dans le tableau ci-dessous. Les plus importants sont en gras et les attributs obligatoires sont en gras et précédés d'un astérisque.
| Attribut | Description |
|---|---|
| *IDENTITY_IMPORT_ID | Il s'agit d'un numéro incrémentiel généré automatiquement par RAC/M Identity pour identifier les identités importées. |
| *FIRST_NAME | Il s'agit du prénom de la personne dont l'identité est créée. Avec les attributs EMPLOYEE_ID et LAST_NAME, c'est l'un des attributs de base dont vous avez absolument besoin pour créer une identité. |
| *LAST_NAME | Il s'agit du nom de famille de la personne dont l'identité est créée. Avec les attributs EMPLOYEE_ID et FIRST_NAME, c'est l'un des attributs de base dont vous avez absolument besoin pour créer une identité. |
| Il s'agit de l'adresse électronique de la personne dont l'identité est créée. Elle vous aide à faire correspondre avec certitude une personne et une identité et peut être utilisée comme clé primaire si plusieurs personnes portent le même nom, par exemple (voir Déterminer une clé primaire). | |
| EMPLOYEE_ID | Il s'agit d'un numéro unique attribué à la personne. Il peut s'agir d'un numéro d'employé, d'un numéro d'étudiant, etc. Généralement, c'est l'attribut le plus important car il est le plus souvent utilisé comme clé primaire (voir Déterminer une clé primaire). |
| HR_JOBS_ID | Il s'agit d'une clé externe unique qui renvoie à la table JOBS, qui contient tous les emplois de votre organisation (par exemple, administrateur, secrétaire, médecin, étudiant, etc.) |
| HR_JOBS_NAME | C'est le nom de l'attribut HR_JOBS_ID tel qu'il est affiché dans la console de gestion de RAC/M Identity. |
| HR_EMPL_STATUS_ID | Il s'agit d'une clé externe unique qui renvoie à la table EMPLOYMENT_STATUS, qui contient tous les statuts d'emploi de votre organisation (par exemple, actif, retraité, congé de maladie, etc.). Il est très important que cet attribut soit renseigné car il détermine si une identité est considérée comme active et si on peut lui accorder un accès. Toutefois, si le champ ne contient aucune donnée, l'identité est considérée comme active par défaut. |
| HR_EMPL_STATUS_NAME | C'est le nom de l'attribut HR_EMPL_STATUS_ID tel qu'il est affiché dans la console de gestion des identités RAC/M. |
| HR_EMPL_TYPE_ID | Il s'agit d'une clé externe unique qui renvoie à la table EMPLOYMENT_TYPE, qui contient tous les types d'emploi de votre organisation (par exemple, permanent, contractuel, stagiaire, etc.). |
| HR_EMPL_TYPE_ID | Nom de l'attribut HR_EMPL_TYPE_ID tel qu'il est affiché dans la console de gestion de RAC/M Identity. |
| TERMINATION_DATE_STR | La date de fin d'emploi est la date à laquelle la personne ne fera plus le travail lié à cette identité. Cette date détermine quand l'identité ne sera plus active. |
| HR_SUPERVISOR_EMPLOYEE_ID | Ceci doit contenir l'ID de l'employé ou un autre identifiant unique pour le gestionnaire ou le superviseur de l'employé. |
| HR_DEPARTMENT_ID | Il s'agit d'une clé externe unique qui renvoie à la table STRUCTURAL_IMPORT. Elle doit faire référence à l'un des départements de votre organisation. |
| HR_ORGANIZATION_ID | Il s'agit d'une clé externe unique qui renvoie à la table STRUCTURAL_IMPORT. Elle doit faire référence à l'une de vos organisations. |
| HR_WORK_LOCATION_ID | Il s'agit d'une clé externe unique qui renvoie à la table STRUCTURAL. Elle doit faire référence à l'un des lieux de travail de votre organisation. |
| HR_WORK_LOCATION_NAME | C'est le nom de l'attribut HR_WORK_LOCATION_ID tel qu'il est affiché dans la console de gestion des identités RAC/M. |
| HR_FILE_SOURCE_ID | Il s'agit d'une clé externe unique qui renvoie à la table FILE_SOURCE. Elle doit faire référence au nom du fichier correspondant à la source d'identité en cours de traitement. |
| BIRTH_DATE_STR | Ce champ facultatif contient la date de naissance de la personne dont l'identité est créée. Il vous aide à faire correspondre une personne à une identité avec certitude si plusieurs personnes portent le même nom, par exemple. |
Note
Tous les attributs commençant par les préfixes HR_, RH_ ou EXT_ et le suffixe _ID sont des clés externes. Cela signifie qu'ils sont utilisés pour faire référence à des données dans une autre table. Comme les données de ces autres tables sont également spécifiques à votre organisation, ces liens sont créés en utilisant la nomenclature de votre organisation. Le nom clés externes reflète le fait que les données liées ne sont pas prédéfinies dans le modèle de RAC/M Identity.
Par exemple, une organisation peut avoir plusieurs statuts pour les identités : terminé, congé maternité, sabbatique et pour chaque entrée, un attribut indique si RAC/M Identity doit conserver ou révoquer les droits. La table des identités sera liée à la table des statuts en utilisant les termes importés de vos données : sabbatique, résilié, etc.
La table STRUCTURAL_IMPORT
La table STRUCTURAL_IMPORT est la table qui décrit la structure et la hiérarchie de votre organisation. Bien que les données qui alimenteront cette table proviennent souvent de la même source que les données qui alimentent la table IDENTITY_IMPORT, elles sont importées à l'aide de collecteurs et de connecteurs différents.
Les principaux attributs sont énumérés dans le tableau ci-dessous. Les plus importants sont en gras et les attributs obligatoires sont en gras et précédés d'un astérisque.
| Attributs | Description |
|---|---|
| *STRUCTURAL_IMPORT_ID | Il s'agit d'une clé unique qui correspond à la colonne HR_DEPARTMENT_ID de la table IDENTITY_IMPORT. Elle vous permet d'identifier les différents éléments structurels (c'est-à-dire l'organisation ou le département) de l'organisation du client. |
| *NAME | Il s'agit du nom de l'élément structurel (c'est-à-dire l'organisation ou le département). |
| *ORG_TYPE | Il identifie si l'élément structurel est une organisation ou un département. |
| HR_WORK_LOCATION_ID | Il s'agit d'une clé externe unique qui renvoie à la table WORK_LOCATION. Elle vous permet d'identifier tous les différents lieux de travail utilisés pour créer la structure. |
| HR_WORK_LOCATION_NAME | C'est le nom du lieu de travail référencé par l'attribut HR_WORK_LOCATION_ID tel qu'il est affiché dans la console de gestion des identités RAC/M. |
La table APPLICATION_ACCOUNT_IMPORT
La table APPLICATION_ACCOUNT_IMPORT est la table dans laquelle toutes les données de vos systèmes et applications cibles sont importées. Elle vous permet d'importer les comptes auxquels les identités ont accès.
Les données sont importées dans cette table à l'aide de collecteurs ou de connecteurs (voir Configurer un collecteur et Connecteurs ICF). Bien qu'il n'y ait généralement qu'un seul collecteur ou connecteur par source de données, il est possible que plusieurs collecteurs ou connecteurs soient nécessaires pour charger les différents types d'objets d'une source de données. Par exemple, différents collecteurs ou connecteurs sont utilisés pour charger les comptes et les groupes d'Active Directory.
Les principaux attributs sont énumérés dans le tableau ci-dessous. Les plus importants sont en gras et les attributs obligatoires sont en gras et précédés d'un astérisque.
| Attributs | Description |
|---|---|
| APPLICATION_ACCOUNT_IMPORT_ID | Il s'agit d'un numéro incrémentiel généré automatiquement par RAC/M pour identifier les comptes importés. |
| *EXT_APPLICATION_ID | Il s'agit d'une clé externe unique liée à la table APPLICATION. Elle permet d'identifier toutes les différentes applications utilisées par les identités. Cet attribut est obligatoire et est souvent une constante, où le nom de l'application est saisi manuellement. |
| *APPLICATION_NAME | Cet attribut est obligatoire et est souvent une constante, où le nom de l'application est saisi manuellement. |
| *ACCOUNT_NAME | Il s'agit du nom d'utilisateur que la personne doit saisir lorsqu'elle se connecte à l'application. Cet attribut est obligatoire et sa valeur doit être unique. |
| *STATUS | Il s'agit de l'état du compte. Il doit indiquer si le compte est actif ou inactif inactif, désactivé. |
| *EXT_APPL_GROUP_ID | Il s'agit d'une clé externe unique qui renvoie à la table APPLICATION_GROUP. Elle vous permet d'identifier tous les différents groupes (ou profils) de sécurité de l'application. Cet attribut est obligatoire. Si l'application n'utilise pas de groupes ou de profils, il faut utiliser une constante, où une valeur est saisie manuellement. |
| APPL_GROUP_NAME | C'est le nom de l'attribut EXT_APPL_GROUP_ID. |
| HR_FILE _SOURCE_ID | C'est une clé externe unique qui renvoie à la table FILE_SOURCE. Elle vous permet d'identifier toutes les différentes sources utilisées pour créer des comptes. |
| EXPIRATION_DATE_STR | C'est la date à laquelle le compte ne sera plus valide. |
| PASSWORD | Il s'agit du mot de passe que la personne doit saisir lorsqu'elle se connecte à l'application. |
| PASSWORD_EXP_DATE | Il s'agit de la date à laquelle le mot de passe ne sera plus valide. |
| IDENTIFIER1 & 2 | Les attributs IDENTIFIER1 et IDENTIFIER2 sont souvent utilisés comme clés secondaires qui aideront à faire correspondre le compte à l'identité. Par exemple, un de ces attributs pourrait être lié à l'attribut EMPLOYEE_ID. |
Remarque
Dans les descriptions des tableaux suivants, le terme Profil fait référence aux profils d'utilisateurs dans les applications ainsi qu'aux groupes de sécurité tels que les groupes Active Directory.
La table profile_hierarchy_import
La table PROFILE_HIERARCHY_IMPORT est la table qui décrit les différents groupes affectés aux comptes d'application au sein de votre organisation. Bien que les données qui alimentent cette table proviennent généralement de la même source que celles qui alimentent la table APPLICATION_ACCOUNT_IMPORT, elles sont importées à l'aide de collecteurs et de connecteurs différents.
Les principaux attributs sont énumérés dans le tableau ci-dessous. Les plus importants sont en gras et les attributs obligatoires sont en gras et précédés d'un astérisque.
| Attributs | Description |
|---|---|
| EXT_APPLICATION_IMPORT_ID | Il s'agit d'une clé externe unique liée à la table APPLICATION. Elle vous permet d'identifier toutes les différentes applications pour lesquelles les profils existent. |
| APPLICATION_NAME | Le nom de l'application référencée par le champ EXT_APPLICATION_IMPORT_ID. |
| ACCOUNT_NAME | Ce champ contient une clé externe unique qui renvoie à la table APPLICATION_ACCOUNT_IMPORT. Elle permet d'identifier le compte auquel un profil spécifique est lié. |
| EXT_PROFILE_ID | Cette clé externe unique est liée à la table PROFILE. Elle vous permet d'identifier tous les différents profils utilisés. |
| PROFIL_NAME | C'est le nom de l'attribut EXT_PROFILE_ID. |
| DESCRIPTION | Il s'agit d'une description du profil. |
Importer des données à l'aide de collecteurs
Les collecteurs sont utilisés pour importer des données depuis des fichiers CSV ainsi que depuis des connecteurs ICF.
Bien que nous recommandions d'importer des données à l'aide de connecteurs qui se connectent directement aux sources d'identités et de données, dans certains cas, vous pouvez être limité à l'utilisation de fichiers plats. C'est le cas si vous mettez en œuvre l'édition RAC/M Identity Gouvernance.
Note
Si les données extraites de l'identité ou de la source de données sont un fichier plat mais pas au format CSV, vous pouvez utiliser des modules spéciaux appelés Formateurs pour convertir le fichier plat au format CSV. Vous pourrez alors traiter le fichier CSV résultant directement avec un collecteur.
Importer un fichier CSV
Pour importer un fichier CSV:
Les prochaines étapes vous guideront pour créer un collecteur qui vous permettra de lire un fichier CSV et de l'importer dans la table d'import de RAC/M Identity.
Dans la barre de menu, cliquez sur CONFIGURATION> Collecteurs.
En haut de la page, cliquez sur le bouton
.Sous Détails, dans les champs Nom et Description, entrez un nom qui reflète ce à quoi le collecteur sera utilisé et entrez une courte description.
Ignorez les champs Fichier de destination et Fichier d'erreur.
Dans le champ Séparateur, entrez le caractère séparateur utilisé dans le fichier CSV d'entrée. Les points-virgules et les virgules sont couramment utilisés.
Dans le champ Encodage du fichier, entrez le format d'encodage du fichier CSV. Si vous laissez le champ vide, le format d'encodage par défaut sera UTF-8.
Note
Il est essentiel d'entrer le bon format d'encodage de fichier pour afficher correctement les caractères accentués et étrangers. Bien que la plupart des fichiers CSV soient encodés à l'aide du codage UTF-8, les fichiers de tableur Microsoft Excel contenant des caractères français canadiens sont généralement encodés à l'aide du codage ISO-8859-1.
Sélectionnez ce que vous voulez que la séquence fasse si des erreurs de traitement sont rencontrées. Vous pouvez choisir d' Arrêter la séquence, Ignorer les opérations restantes dans ce bloc et continuer la séquence à partir du bloc suivant ou simplement Continuer avec l'opération suivante.
Pour l'instant, vous pouvez laisser le choix par défaut d'arrêter tout traitement lorsque des erreurs sont rencontrées.
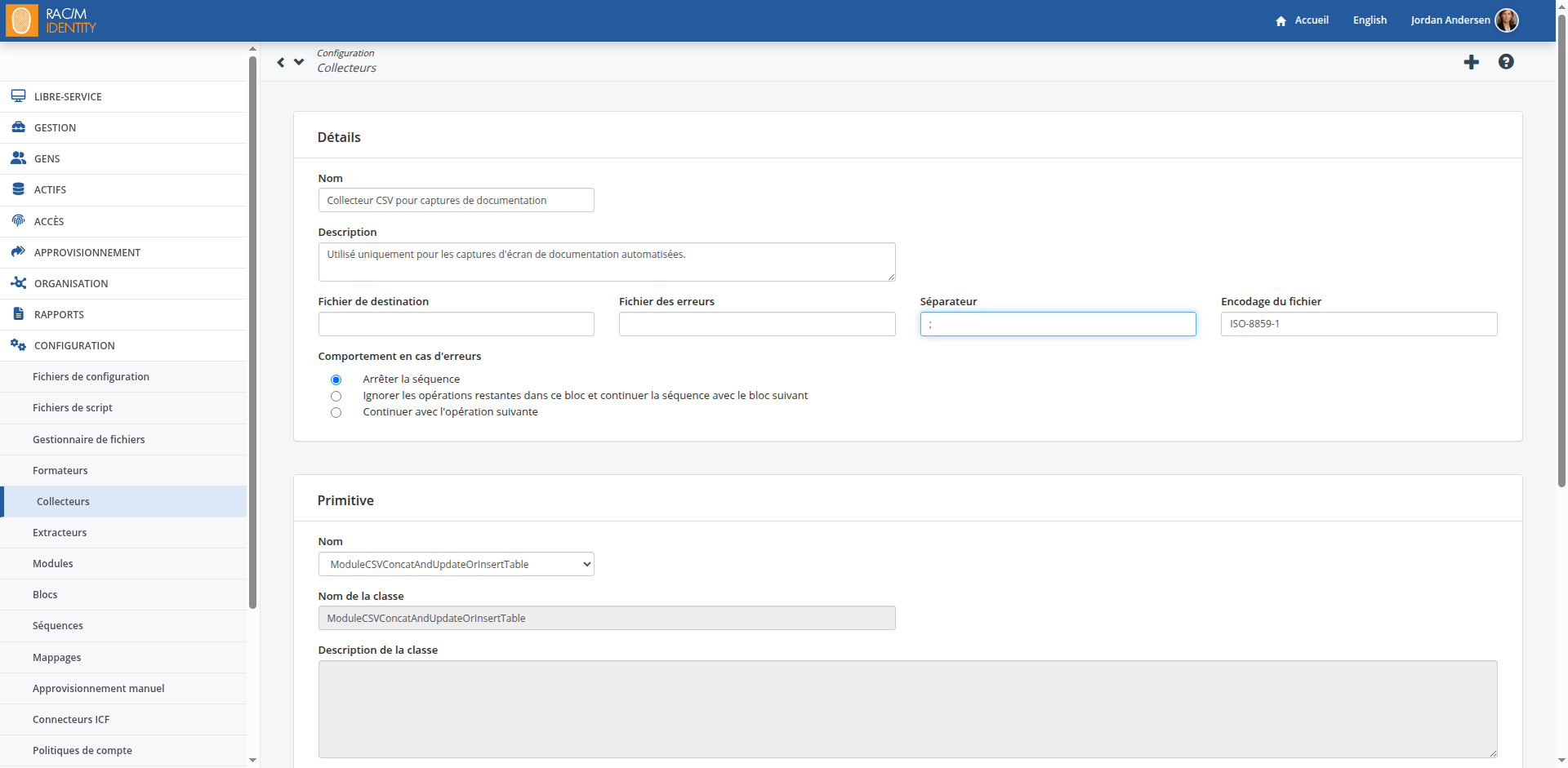
Sous Primitive, dans le champ Nom, sélectionnez la primitive à utiliser pour importer les données. Les primitives qui peuvent être utilisées pour importer des fichiers CSV comportent les caractères CSV dans leur nom. Pour l'instant, sélectionnez la primitive ModuleCopyCSVToTable. Elle effectuera une simple copie du fichier CSV source vers la table d'import.
Sous Importation de données, dans la liste Table cible, sélectionnez la table dans laquelle vous voulez importer les données.
Pour commencer, nous vous recommandons d'importer les données de base dans les principales tables d'import décrites ci-dessus telles que:
- IDENTITY_IMPORT
- APPLICATION_IMPORT
- APPLICATION_ACCOUNT_IMPORT
- ENTERPRISE_IMPORT
- PROFILE_IMPORT
- RESOURCE_IMPORT
- STRUCTURAL_IMPORT
Au fur et à mesure que vous vous familiariserez avec RAC/M Identity et son modèle de données, vous serez en mesure d'importer des données dans d'autres tables.
Dans la liste Fichier source, sélectionnez le fichier à partir duquel vous souhaitez importer les données. Par exemple, pour importer la liste des employés à l'emploi de votre entreprise, sélectionnez un fichier en format CSV qui contient les informations pertinentes pour représenter chacun des employés et leur statut d'emploi, telles que leur nom, prénoms, titre, statut, département, superviseur, etc.. Chacun des champ sera importé dans la colonne correspondante des tables d'import. Vous pouvez examiner les colonnes du fichier source lorsque vous ouvrez une liste Colonne source.
Le champ Type permet de sélectionner le format du fichier à importer. RAC/M Identity est capable de déterminer automatiquement le format du fichier dans la plupart des cas. Pour laisser RAC/M déterminer automatiquement le format du fichier, laissez le champ à Détecter automatiquement. Pour sélectionner un format spécifique, choississez le dans la liste déroulante.
La façon dont les colonnes sont représentées dépend de la façon dont le fichier est structuré. Si le fichier CSV d'entrée contient une première ligne contenant des en-têtes de colonne, sélectionnez En-tête dans le Type d'en-tête de colonne. Si le fichier ne contient pas de ligne d'en-tête, il est possible de fournir un fichier modèle qui décrit les colonnes. Si un fichier modèle est disponible, sélectionnez-le dans le champ Fichier modèle de la source, sinon, sélectionnez Index dans le champ Type d'en-tête de colonne. Dans ce cas, un numéro d'index sera utilisé pour référencer chaque colonne, en commençant par 1.
Cliquez sur Charger les colonnes depuis la table et le fichier source.
Pour chaque champ de la table cible dans laquelle vous souhaitez importer des données, sélectionnez un type de données dans la liste du champ Type de source de données.
Le choix Colonne indique que la valeur sera fixée à la valeur de la colonne sélectionnée dans le fichier source.
Note
Il est également possible de sélectionner des types de données avancés tels que des constantes, des valeurs prédéfinies, des valeurs hachées, des valeurs masquées et des combinaisons de valeurs. Les formats peuvent également être spécifiés pour déterminer comment les données sont représentées dans la table cible. L'utilisation des types de données avancés est décrite à la section 3.
Voir aussi
Pour chaque champ de la table cible dans laquelle vous souhaitez importer des données, sélectionnez le nom de la colonne du fichier source correspondant.
Cliquez sur Enregistrer pour enregistrer le nouveau collecteur.
Conseil
Si les données importées d'un fichier CSV contiennent des caractères accentués ou étrangers qui ne sont pas représentés correctement dans RAC/M Identity, cela est probablement dû à un format d'encodage incorrect. Veuillez trouver quel format d'encodage est utilisé dans le fichier source et entrez-le dans le champ Encodage du fichier.
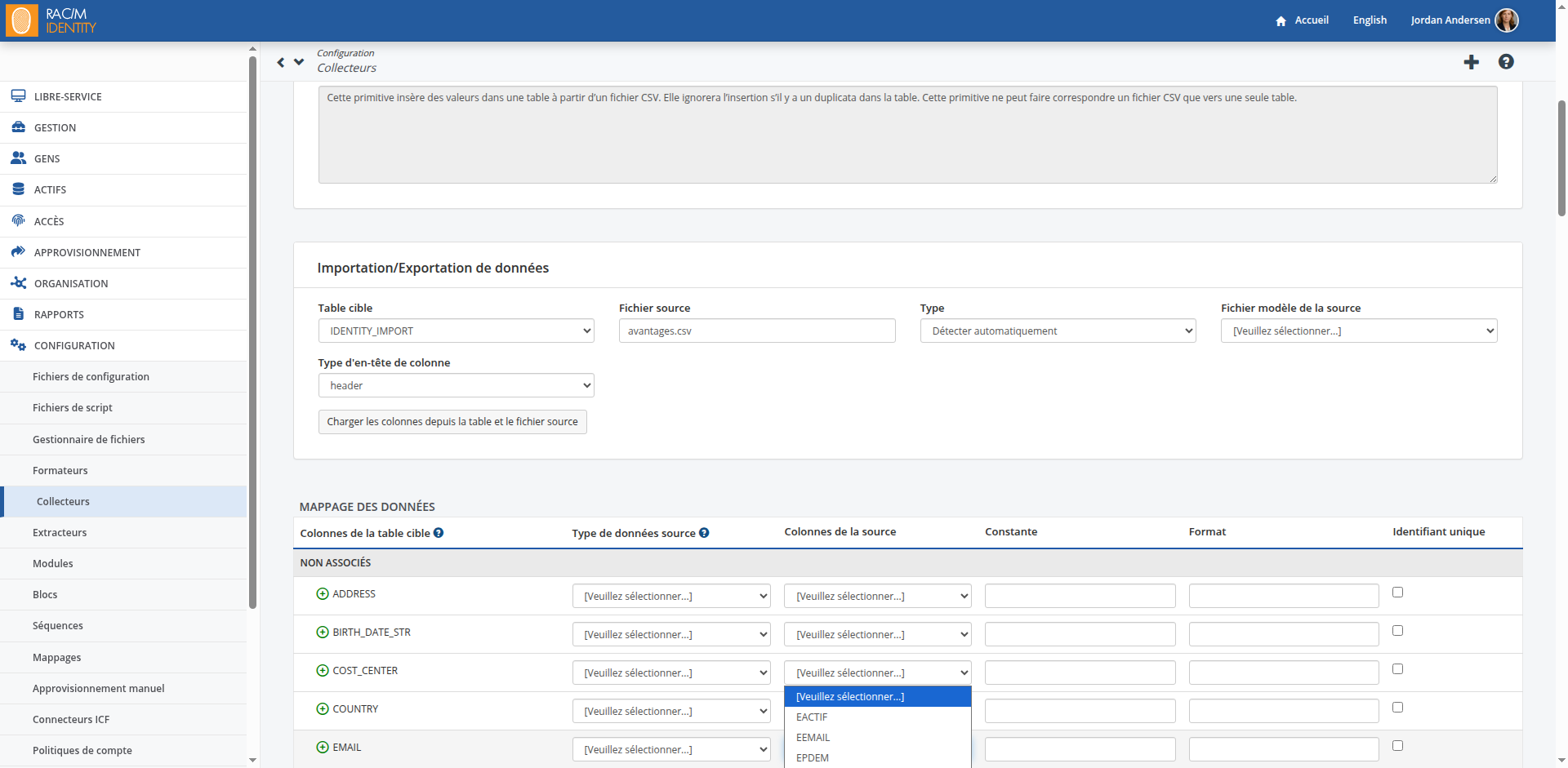
Conseil
Vous pouvez également ouvrir les fichiers plats à l'aide d'autres logiciels. Parfois, cela permet d'examiner plus facilement le contenu du fichier. Nous vous recommandons, lorsque vous analysez un fichier CSV, de l'ouvrir à l'aide de Microsoft Excel, cela vous permet de voir les données organisées en colonnes et non comme une série de valeurs séparées par une virgule ou un point-virgule.
Note
Lorsque vous ouvrez un fichier dans des applications telles que Microsoft Excel, veillez à que vous conservez le codage (par exemple, ISO-8859-1 ou UTF-8) utilisé pour créer le fichier, sinon, certains textes contenant des caractères accentués, pourraient ne pas apparaître correctement.
Importer des données à l'aide de connecteurs
La première chose à faire lorsqu'on prévoit d'utiliser un connecteur pour extraire des données d'une source d'identité ou d'un système cible est d'identifier la source de données réelle.
Il peut s'agir d'une base de données SQL, comme celle utilisée pour la plupart des systèmes RH, d'un annuaire LDAP, comme c'est souvent le cas lorsque Active Directory est utilisé comme source d'identités pour les contractuels, ou d'une API exposée pour la gestion des applications en nuage.
Les connecteurs ICF servent à connecter à des sources de données, mais ils peuvent également être utilisés pour traiter des fichiers complexes tels que les IDocs SAP.
Note
La configuration des connecteurs ICF est un sujet avancé qui sera abordé plus loin. Pour commencer à utiliser RAC/M Identity, nous recommandons d'utiliser des collecteurs avec des fichiers CSV. Une fois que vous serez familiarisé avec les concepts et le fonctionnement de RAC/M Identity, il sera beaucoup plus facile de configurer les connecteurs ICF avec une logique d'affaires avancée.
Voir aussi
Note
Dans tous les cas, il est important de documenter les détails spécifiques nécessaires pour établir la connexion et récupérer les données à l'aide d'un formulaire d'intégration tel que les feuilles de calcul qui se trouvent dans le répertoire de distribution de votre site de support client désigné.
Conseil
Même si un connecteur sera utilisé pour collecter les informations, il peut être utile d'extraire temporairement les informations à l'aide d'un fichier plat et d'utiliser un outil tel qu'Excel pour visualiser les attributs ou le contenu des colonnes.
L'utilisation de ces outils vous permettra de visualiser et d'analyser les données de la même manière que si des collecteurs étaient utilisés.
Pour créer un collecteur utilisant un connecteur
Dans la barre de menu, cliquez sur CONFIGURATION> Collecteurs.
En haut de la page, cliquez sur le bouton
.Sous Détails, dans les champs Nom et Description, entrez un nom qui reflète ce à quoi le collecteur sera utilisé et entrez une courte description.
Ignorez les champs Fichier de résultat, Fichier d'erreur et Séparateur.
Dans le champ Encodage du fichier, entrez le format d'encodage des données source. Si vous laissez le champ vide, le format d'encodage par défaut sera UTF-8.
Note
La saisie du format d'encodage correct du fichier est essentielle pour afficher correctement les caractères accentués et étrangers.
Sélectionnez ce que vous voulez que la séquence fasse si des erreurs de traitement sont rencontrées. Vous pouvez choisir d' Arrêter la séquence, Ignorer les opérations restantes dans ce bloc et continuer la séquence à partir du bloc suivant ou simplement Continuer avec l'opération suivante.
Pour l'instant, vous pouvez laisser le choix par défaut d'arrêter tout traitement lorsque des erreurs sont rencontrées.
Sous Primitive, dans le champ Nom, sélectionnez la primitive à utiliser pour importer les données. Les primitives qui peuvent être utilisées pour importer des connecteurs ICF comportent les caractères ICF dans leur nom. Pour l'instant, sélectionnez la primitive ModuleICFImportData. Cela permettra d'effectuer une importation simple à l'aide d'un connecteur ICF vers une source de données.
Laissez le champ Enregistrer uniquement sur Faux.
Sous Importation de données, dans la liste Table cible, sélectionnez la table dans laquelle vous voulez importer les données.
Cliquez sur Charger les colonnes depuis la table et le fichier source pour charger la liste des attributs du système cible mis à disposition par le connecteur ICF. Vous pourrez ensuite mapper ces attributs à la colonne appropriée dans la section MAPPAGE DES DONNÉES ci-dessous.
Note
Il est également possible de sélectionner des types de données avancés tels que des constantes, des valeurs prédéfinies, des valeurs hachées, des valeurs masquées et des combinaisons de valeurs. Les formats peuvent également être spécifiés pour déterminer comment les données sont représentées dans la table cible.
L'utilisation des types de données avancés est décrite dans le guide d'administration et d'opérations de RAC/M Identity.
Voir aussi
- Pour chaque champ de la table cible dans laquelle vous souhaitez importer des données, sélectionnez le nom de la colonne du fichier source correspondant.
Conseil
Pour commencer, nous vous recommandons d'importer des données de base dans les principales tables d'import décrites ci-dessus. Les tables d'import contiennent le mot "IMPORT" dans leur nom. Ex : IDENTITY_IMPORT.
Au fur et à mesure que vous vous familiariserez avec RAC/M Identity et son modèle de données, vous serez en mesure d'importer des données dans d'autres tables.
Identifier les erreurs et les données non valides
Dans un scénario idéal, toutes les données trouvées dans le fichier CSV, et par conséquent dans le référentiel RAC/M, ne contiennent pas d'erreurs ou de données invalides. Ce n'est cependant jamais la réalité. RAC/M vous permet d'ignorer certaines erreurs qui n'affectent pas l'importation des données ni leur utilisation.
Les paragraphes suivants présentent quelques erreurs courantes. Lorsque des erreurs sont constatées, il est important d'avoir accès aux experts de domaine responsables de l'identité et des sources de données, afin de déterminer la cause des erreurs et la manière de les corriger.
Voici quelques erreurs que vous pouvez rencontrer :
Colonnes décalées
Si vous remarquez que le contenu d'une colonne ne correspond pas à l'en-tête, il se peut que les colonnes aient été déplacées (le contenu de la colonne 1 peut se trouver dans la colonne 2). Cela a pu se produire lors de la conversion ou si des guillemets (" ") sont utilisés. En effet, RAC/M prend en charge l'utilisation des guillemets pour indiquer que tout ce qui se trouve à l'intérieur est du texte et que les virgules ou les points-virgules ne sont pas considérés comme des séparateurs. Vous devez rechercher la raison de ce décalage et le corriger.
Formats de date
Le format des champs de date dans une colonne donnée d'un fichier CSV doit être le même pour toutes les valeurs de la colonne. Toutefois, le format peut varier d'une colonne à l'autre. Le format exact, qui peut être quelque chose comme dd/mm/yyy, mm/dd/yyyy, dd-mm-yyy, etc. n'est pas critique. Si le format n'est pas cohérent, l'importation et le traitement échoueront et les erreurs devront être corrigées pour terminer le processus.
Une fois que vous avez déterminé que toutes les dates d'une colonne donnée utilisent un format spécifique, vous pouvez le définir comme paramètre de format lors de la définition du collecteur associé. Cette opération s'effectue à partir de la barre de menu, Configuration> Collecteurs, sous DATA MAPPING.

Erreurs de frappe
Celles-ci peuvent ou non devoir être corrigées selon que la valeur est une clé ou non et que l'erreur est cohérente ou non.
Exemple
Si votre clé est le nom de l'hôpital "St. Mary's Hospital", mais que "St. Mary's Hospital" est parfois aussi orthographié "St. Marie's Hospital". Le nom n'est pas normalisé, par conséquent, deux entrées différentes seront créées pour le même hôpital.
Par contre, si le vrai nom est " St. Mary's Hospital ", mais qu'il a été constamment entré sous la forme " St. Marie's Hospital ", il n'est pas nécessaire de le corriger, car une seule entrée sera créée. Cette coquille, bien qu'elle puisse irriter les utilisateurs de l'interface RAC/M, n'affectera pas les données, ni la façon dont elles sont importées et utilisées.
La manière de corriger les données dépend de leur nature. Les données d'identité liées au nom d'une personne n'ont peut-être pas besoin d'être corrigées puisque RAC/M Identity fera automatiquement correspondre les différentes orthographes, même incorrectes, chaque fois que les données sont mises à jour.
Pour les informations de référence telles que la structure organisationnelle et la structure de travail, il est généralement préférable d'apporter des corrections à la source d'information.
A propos des utilisateurs de RAC/M Identity
Il existe deux types de comptes utilisateurs RAC/M Identity: Les utilisateurs locaux qui ne sont généralement utilisés que pour la configuration initiale et la mise en place de RAC/M Identity et les comptes utilisateurs fédérés qui sont utilisés au quotidien par les pilotes, les utilisateurs finaux, les opérateurs, les gestionnaires, les approbateurs, les certificateurs, etc. pour effectuer des opérations GIA et gérer une mise en œuvre opérationnelle de RAC/M Identity.
Les comptes locaux sont créés à partir de la console d'administration et sont authentifiés à l'aide de la base de données de mots de passe intégrée. Il ne devrait normalement y avoir qu'un très petit nombre de comptes locaux, idéalement un seul. Les comptes locaux ne sont normalement utilisés que pour l'installation et la configuration initiales de RAC/M Identity.
Les comptes fédérés n'ont pas besoin d'être créés manuellement car ils sont importés d'un annuaire d'entreprise tel qu'Active Directory ou Entra ID. Les comptes fédérés sont authentifiés à l'aide d'un mécanisme d'authentification externe tel qu'Active Directory ou un fournisseur d'authentification SAML et affectés par des règles d'affaires au profil RAC/M Identity approprié en fonction de leurs responsabilités.
Conseil
Une fois qu'un fournisseur d'authentification tel qu'Active Directory ou un IDP SAML est configuré, la meilleure pratique recommandée est que les comptes locaux soient associés à des identités existantes et authentifiés à l'aide d'un fournisseur d'authentification fédérée plutôt que de la base de données de mots de passe interne.
Une fois qu'un fournisseur d'authentification fédérée a été activé et que tous les comptes locaux ont été associés à une identité, le mécanisme interne d'authentification par mot de passe peut être désactivé.
A propos des profils de RAC/M Identity
Dans RAC/M Identity, les profils vous permettent de définir à quels menus et fonctionnalités les utilisateurs auront accès. Ceci est utile pour limiter ce que certains utilisateurs peuvent voir et faire dans la console de gestion en fonction de leurs responsabilités.
Voir aussi
À propos des rôles
Cette section présente les grandes lignes du modèle de rôles supporté par RAC/M Identity.
Dans RAC/M Identity, un rôle est une façon de modéliser les accès en les regroupant et en leur donnant un nom logique. Les rôles peuvent être cumulatifs et toutes les personnes ayant le même rôle ont les mêmes droits. Par exemple, les rôles peuvent correspondre à la notion d'"Emploi" ou de "Titre", notamment au sein des entreprises.
Une fois que le référentiel a atteint un niveau de qualité suffisant et est alimenté par des données fiables, vous pouvez commencer à analyser les droits existants pour définir les rôles pertinents pour votre organisation.
Rôles statiques
Les rôles statiques sont liés explicitement à chaque identité. Cela signifie que si, par exemple, la fonction ou le rôle d'une identité change au sein de l'organisation, l'ancien rôle restera lié à l'identité jusqu'à ce qu'il soit explicitement supprimé.
Exemple
John Smith est un développeur auquel un rôle statique est assigné. Lorsqu'il devient gestionnaire, il a besoin d'accéder à certaines applications de suivi du temps, mais les changements ne se font pas automatiquement. Le pilote de RAC/M Identity devra utiliser manuellement la console d'administration ou appliquer la logique d'affaire pour effectuer les modifications.
Cela correspond au modèle classique de contrôle d'accès basé sur les rôles (RBAC) ANSI/INCITS 359-2012, mais il est souvent difficile de le faire évoluer vers des organisations de moyenne ou grande taille, car les changements organisationnels doivent être reproduits dans les rôles manuellement. Ce modèle est plus adapté aux organisations où les rôles sont peu nombreux et très stables.
Rôles dynamiques
Les rôles dynamiques sont attribués automatiquement aux identités sur la base de règles d'affaires qui interrogent des attributs. Par exemple, cela permet aux identités qui se déplacent dans l'organisation et obtiennent un nouveau titre de se voir automatiquement attribuer des rôles pertinents.
Ils peuvent aussi servir à attribuer automatiquement des rôles de base, parfois appelés birthrights (droits à la naissance), lorsque des personnes rejoignent l'organisation.
Ce modèle apporte les avantages du contrôle d'accès basé sur les attributs (ABAC) en s'appuyant sur des règles d'affaires flexibles, définies par l'utilisateur. Par exemple, le rôle "gestionnaire" peut être attribué avec une règle du genre: SI le titre du demandeur est "gestionnaire" ALORS on lui attribue le rôle "Gestionnaire". Ce modèle est bien adapté aux moyennes et grandes organisations où les restructurations ou les mouvements de personnel sont fréquents.
Lorsqu'un nouveau rôle est créé ou extrait, par défaut un critère qui vérifie si l'identité est active est ajouté par défaut au rôle. Ceci afin de s'assurer que le rôle n'est attribué qu'aux identités actives uniquement, car c'est le cas d'usage le plus courant. Ce critère peut être supprimé ou modifié si désiré.
Rôles hybrides
Les rôles hybrides combinent les caractéristiques des rôles statiques et dynamiques. Il permet d'ajouter certains membres directement à un rôle autrement dynamique (par exemple, si une personne du département A travaille temporairement dans le département B).
Versions de rôle
Dans RAC/M Identity, la notion de versions permet de garder l'historique et la traçabilité de l'évolution d'un rôle dans le temps. Les versions permettent aussi d'isoler le processus de modélisation et d'évolution de la prodution de sorte à éviter tout impact non intentionnel durant les activités de modélisation. A cet effet, une seule version du rôle peut être active ce qui évite toute confusion et permet un retour arrière simple et rapide si requis.
Les différentes versions de rôles se distinguent l'une de l'autre par un numéro séquentiel, automatiquement généré, qui leur assigné lors de leur création.
Modification d'un rôle
Il existe deux méthodes pour procéder à des changements sur un rôle existant :
Utilisation des versions dans la page des détails des versions du rôle.
Veuillez vous référer à Créer une nouvelle version de rôle pour modifier un rôle, puis procéder à son activation.
Note
Cette méthode de modification d'un rôle est uniquement disponible pour les administrateurs. De plus, cette modification ne suit pas le processus d'approbation de l'autre méthode. Veuillez l'utiliser avec précaution. Les versions créées seront en mode "lecture seule" pour les administrateurs tant que la demande est en cours.
Utilisation des demandes dans le libre-service.
Pour commencer le processus de modification, veuillez vous référer à Demandes de modification de rôle. Lorsqu'une demande est soumise, une nouvelle version est créée pour représenter les changements apportés à ce rôle. Cette requête sera soumise à un processus d'approbation basé sur les modifications demandées (À propos des flux d'approbation).
Une fois l'approbation de la demande complétée, le rôle est prêt à être activé pour que les changements prennent effet. L'activation peut être automatique ou nécessiter une action manuelle de la part des responsables de la gestion des identités et des accès (GIA). Le type d'activation par défaut est défini par la propriété
self.service.workflow.role.default_activation_optiondans le fichierconfig.properties, mais peut être modifié lors de la tâche d'approbation globale.- Activation automatique : La version sera activée lors de la prochaine exécution du module d'activation. Veuillez vous référer aux modules.
- Activation manuelle : Une notification par courriel sera envoyée au responsable pour indiquer que l'activation est en attente. Ce groupe de délégation est défini dans la propriété
self.service.workflow.role.giadu fichierconfig.properties.
Provisionnement des rôles
Le provisionnement des rôles est le processus d'attribution de droits aux identités basé sur les rôles. Ce processus implique plusieurs étapes et est détaillé ici pour aider les intégrateurs et les administrateurs à comprendre le processus.
Toutes les opérations de provisionnement sont basées sur la différence entre la version actuellement active et la nouvelle version à activer. Seules les différences entre les deux versions sont prises en compte. Ceci inclut les différences dans les accès donnés par le rôle et les différences dans les membres du rôle. Par exemple, si un membre est ajouté, tous les accès du rôle lui seront provisionnés et si un accès est ajouté au rôle, tous les membres du rôle recevront cet accès.
Exemple
Considérez une identité nommée Joe qui a le rôle "Opérateur" qui accorde le profil "Opérer" dans l'actif "Machine". Cependant, pour une raison quelconque, le compte de Joe dans "Machine" n'a pas actuellement ce profil même s'il a le rôle "Opérateur".
Disons que son gestionnaire Manny ajoute un autre profil "Maintenance" dans une nouvelle version du rôle "Opérateur" et l'active. RAC/M Identity provisionnera alors le profil "Maintenance" au compte de Joe dans "Machine" mais ne provisionnera pas le profil "Opérer". C'est parce qu'il n'y a pas eu de changement pour le profil "Opérer" entre les deux versions.
Cette règle a quelques cas spéciaux :
- Quand il n'y a pas de version actuellement active, elle est traitée de la même manière que s'il y avait une version active vide sans identités ni droits.
- Désactiver un rôle est traité de la même manière que créer une nouvelle version vide et l'activer.
- Dans le portail libre-service, une demande d'attribution d'un rôle à une identité sera traitée de la même manière que si une nouvelle version du rôle avec cette identité ajoutée dans les membres statiques était créée et activée. En réalité, il n'y a pas de nouvelle version créée, le code de provisionnement traite simplement ce cas de la même manière.
Avertissement
Les impacts des cas 1 et 2 sont importants. Vous ne devriez pas désactiver un rôle avant d'activer une nouvelle version. Cela causerait à RAC/M Identity de déprovisionner tous les droits du rôle actuellement actif de toutes les identités du rôle et ensuite provisionner tous les droits du nouveau rôle à toutes les identités du rôle.
Cela créerait beaucoup de travail inutile et des problèmes avec les personnes perdant temporairement certains accès.
Provisionnement des changements dynamiques
Les rôles dynamiques assignent des membres basés sur des critères, mais pour des raisons d'efficacité, ces critères ne sont pas évalués à chaque changement de données dans le référentiel. Les critères sont évalués par un processus appelé "Intégrité des rôles". Quand une identité ou un rôle est modifié explicitement dans la console d'administration, le processus "Intégrité des rôles" est lancé en se concentrant sur l'identité ou le rôle modifié.
Dans les séquences de traitement des données de RAC/M Identity, les données changent continuellement et il serait trop inefficace d'évaluer les critères à chaque changement. Il y a donc un module spécial appelé "ModuleRoleIntegrity" qui est utilisé pour évaluer les critères et déclencher le provisionnement quand des changements sont détectés. Ce module peut être ajouté dans n'importe quelle séquence.
Processus de provisionnement
Le processus commence par une étape appelée "Explosion des rôles" dans laquelle tous les changements au rôle sont "explosés" et appliqués aux identités du rôle. Ceci n'est pas trivial car une nouvelle identité dans le rôle doit recevoir tous les droits du rôle alors qu'une identité existante doit recevoir seulement les changements aux droits. Cette étape crée des "Demandes de provisionnement de compte" et des "Demandes de provisionnement de profil" pour chaque changement au rôle. Ces demandes dérivées seront ensuite traitées par d'autres modules dans la séquence de la même manière que toute autre demande de changement aux droits d'une identité.
À propos d'authentification fédérée
Note
Cette section ne s'applique que si vous installez RAC/M Identity sur site, car RAC/M Identity en mode SaaS est toujours préconfiguré lors de l'activation pour effectuer l'authentification fédérée des utilisateurs, généralement avec SAML et votre instance ENTRA ID ou avec votre Active Directory.
Dans le cas d'une installation sur site ou si vous utilisez votre propre locataire Microsoft Azure, la section suivante vous guidera dans la configuration de RAC/M Identity pour utiliser l'authentification fédérée.
Reportez-vous au Guide SSO ENTRA ID (SAML) pour obtenir des instructions sur la configuration d'ENTRA ID afin d'autoriser l'authentification SAML vers votre instance ENTRA ID.
Authentification avec SAML
Si vous utilisez ENTRA ID, ou un autre service de fournisseur d'identité (IDP) vous pouvez l'utiliser comme source d'identité pour authentifier les utilisateurs de RAC/M Identity. Vous devez éditer les propriétés correspondantes du fichier config.properties. pour activer l'authentification SAML.
Pour modifier le fichier config.properties:
- Avec un éditeur de texte, ouvrez le fichier
conf\config.properties. - Modifiez les propriétés suivantes :
auth.saml.enabled=true
auth.saml.relyingPartyIdentifier=${App ID}
auth.saml.metadataUrl=${App Federation Metadata Url}
auth.saml.replyURL=${ReplyURL}
auth.saml.app.id=${ID de l'actif RACM contenant les comptes Entra ID}
auth.saml.username.racm.column.name=${Le nom de la colonne dans la table APPLICATION_ACCOUNT où le nom de compte Entra ID se trouve. ex: ACCOUNT_NAME}Exemple
Les propriétés pourraient être écrites comme suit :
auth.saml.enabled=true
auth.saml.relyingPartyIdentifier=api://RACMDEMO1-SAML
auth.saml.metadataUrl=https://login.microsoftonline.com/2b84024c-25a3-447b-9a4a-e9d5b6d5370d/federationmetadata/2007-06/federationmetadata.xml?appid=30c741ed-742e-4b46-858e-f8f56cd47fad
auth.saml.replyURL=https://demo1.racmidentity.com/gui/loginSamlCallback.action
\## RACM Application ID which holds the accounts accounts used for the SAML auth
auth.saml.app.id=444
\## The APPLICATION_ACCOUNT column name which contains the SAML username/SubjectID
auth.saml.username.racm.column.name=ACCOUNT_NAMEUn guide explicatif sur la configuration d'ENTRA ID pour permettre l'authentification SAML vous est fourni dans votre répertoire de support afin que vous puissiez le transmettre aux administrateurs d'ENTRA ID. Ceux-ci devront effectuer le paramétrage recommandé afin d'activer l'authentification SAML à partir de votre instance d'ENTRA ID.
Enregistrez le fichier et redémarrez le serveur de RAC/M Identity.
Authentification avec Active Directory
Si vous utilisez déjà Microsoft Active Directory pour gérer des utilisateurs, des groupes, des ordinateurs, etc., vous pouvez le connecter à RAC/M Identity à des fins d'authentification. Vous devez d'abord l'importer dans le référentiel ainsi que les identités correspondantes et, ensuite, vous devez éditer le fichier config.properties. pour activer l'authentification avec Active Directory.
Pour modifier le fichier config.properties:
- Avec un éditeur de texte, ouvrez le fichier
conf\config.properties. - Modifiez les propriétés suivantes :
contextsource.ldap.search=false
contextsource.ldap.config.url=ldap://[hôte du serveur ldap] :[port du serveur ldap]
contextsource.ldap.config.base=[dn d'authentification]
contextsource.ldap.config.username=[dn de l'utilisateur administrateur<u>]</u>
contextsource.ldap.config.password=[Mot de passe de l'utilisateur administrateur]
contextsource.ldap.config.pool=true
contextsource.ldap.config.attribut.login=[attribut de login]
active.directory.application.id=[ID de l'application RACM]Exemple
Les propriétés pourraient être écrites comme suit :
contextsource.ldap.search=false
contextsource.ldap.config.url=ldap://192.168.0.1:389
contextsource.ldap.config.base=DC=mystructure,DC=sfiler,DC=com
contextsource.ldap.config.username=CN=Administrator, CN=USERS,DC=mystructure,DC=sfiler,DC=com
contextsource.ldap.config.password=mypassword
contextsource.ldap.config.pool=true
contextsource.ldap.config.attribut.login=SAMAccountName
active.directory.application.id=2- Enregistrez le fichier et redémarrez le serveur de RAC/M Identity.
Gestion des mots de passe dans RAC/M Identity
RAC/M Identity intègre le moteur PWM (standard de l'industrie) pour fournir un portail de gestion des mots de passe en libre-service sécurisé et convivial. Ce module permet aux utilisateurs de gérer leurs identifiants, de déverrouiller des comptes et de réinitialiser des mots de passe sans avoir besoin de contacter le service d'assistance. Cette fonctionnalité est optionnelle et peut être activée ou désactivée dans le fichier config.properties.
Fonctionnalités principales
Réinitialisation de mot de passe en libre-service (SSPR)
Les utilisateurs qui ont oublié leur mot de passe ou qui ont été verrouillés de leurs comptes peuvent retrouver l'accès de manière sécurisée.
- Mot de passe oublié : Lance un flux de travail sécurisé pour réinitialiser un mot de passe perdu.
- Déverrouiller le compte : Permet aux utilisateurs de déverrouiller leur compte d'annuaire (par exemple, Active Directory) s'il a été verrouillé en raison de trop nombreuses tentatives de connexion échouées.
- Méthodes de vérification : L'identité est vérifiée via des questions de sécurité préconfigurées, des jetons SMS ou des codes d'accès à usage unique (OTP) par courriel.
Changement de mot de passe de routine
Les utilisateurs peuvent changer de manière proactive leurs mots de passe actuels avant qu'ils n'expirent.
- Synchronisation : Les modifications effectuées ici sont automatiquement synchronisées sur tous les systèmes cibles connectés (AD, LDAP, ERP) gérés par RAC/M Identity.
- Retour en temps réel : L'interface fournit un retour immédiat sur la correspondance et la validité de la saisie du mot de passe.
Application des politiques de mot de passe
Le portail garantit que tous les nouveaux mots de passe respectent les normes de sécurité de l'organisation.
- Indicateur de force : Des indicateurs visuels montrent la force du mot de passe choisi.
- Validation des règles : Empêche l'utilisation de mots de passe faibles en vérifiant l'historique (empêchant la réutilisation), les mots du dictionnaire et les exigences de complexité (longueur, caractères spéciaux, etc.).
Configuration du profil de récupération
Les utilisateurs peuvent gérer leurs propres paramètres de sécurité pour s'assurer qu'ils peuvent récupérer leur compte à l'avenir.
Comment y accéder
Les fonctionnalités de gestion des mots de passe sont intégrées directement dans le portail libre-service de RAC/M Identity.
Navigation :
- Si vous êtes connecté : Cliquez sur Gestion des mots de passe pour accéder à PWM et changer votre mot de passe ou modifier votre profil de récupération.
- Si vous êtes verrouillé : Cliquez sur le lien "Mot de passe oublié ?" sur l'écran de connexion.
À propos de l'API REST de RAC/M Identity
RAC/M Identity expose une API REST sécurisée qui permet à des solutions externes d'interagir de façon programmatique avec les objets du référentiel, tels que les Identités, les Comptes, les Rôles, les Droits d'accès et les demandes d'accès. L'API utilise OAuth 2 pour l'authentification et applique les mêmes contrôles d'autorisation et d'audit que l'interface web, de sorte que les intégrations externes opèrent dans le même périmètre de sécurité que les utilisateurs humains.
Un cas d'utilisation courant est l'intégration avec une solution ITSM : le système ITSM peut interroger l'API pour rechercher les rôles et les droits d'accès disponibles, puis créer des demandes d'accès ou de cessation au nom d'un utilisateur, de manière semblable à ce que les utilisateurs peuvent faire directement via le portail libre-service. Parmi les autres usages typiques, on trouve la synchronisation avec des plateformes de billetterie, des systèmes RH et des flux d'automatisation personnalisés.
La référence complète de l'API, incluant les points d'accès disponibles, les schémas de requêtes et de réponses ainsi que les détails d'authentification, est publiée ici : Référence de l'API REST de RAC/M Identity.